在完成Python安裝後,接下來就需要選擇一個開發工具來撰寫程式碼,目前市面上的開發工具有很多,像是Sublime、Visual Studio Code、Atom、PyCharm等,各自都有其優點,沒有哪一個工具一定最好,只要依照個人喜好進行選擇就可以了。本篇就以Windows平台為例,介紹如何在Visual Studio Code(簡稱VSCode)中建置Python的開發環境。為什麼會推薦使用VSCode呢?除了它是一個較輕量的開發工具以外,它還具有以下的特點。

一、VSCode特色
1. Intellisense(智慧語法提示)
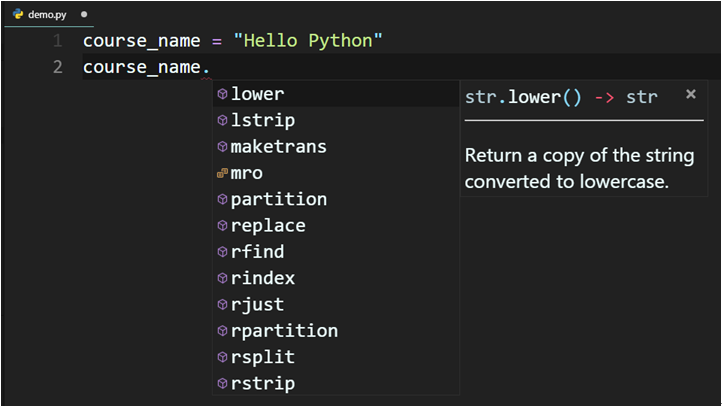
於撰寫程式碼時,VSCode會提示此物件能使用的各種屬性(Property)及方法(Method),並且會顯示該方法的簡要說明及回傳的型別。點選需要的方法後,自動完成,無須逐字Key完所有的字母,大幅提高撰寫程式碼的效率。
2. Debugging(偵錯功能)
VSCode擁有出色的偵錯功能,能將中斷點下在可能出問題的程式碼列,並於偵錯模式中,逐步的執行程式碼,左欄視窗會依據執行的過程顯示各個變數目前的數值,減少開發人員除錯的時間。

3. Bult-in Git(內建Git)
VSCode內建Git原生的功能,包含常用的如Pull、Push、Commit及不同版本程式碼的異動比較等,讓我們在程式撰寫的過程中,易於進行版本控管。

4. Code Formatting(程式碼排版)
在稍後教大家安裝Python套件後,VSCode會在儲存的時候,依據Python官方的程式碼撰寫風格原則(PEP8 - Style Gide for Python Code)自動幫我們排版程式碼,提高程式碼的可讀性。
5. Linting(程式碼檢查)
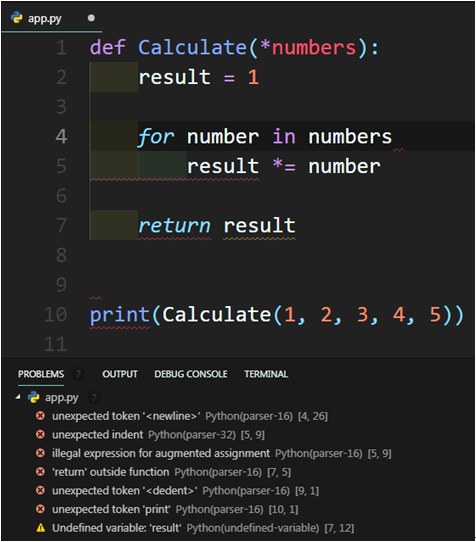
同樣的安裝完Python套件後,VSCode的Linting功能在我們撰寫程式的過程中,分析我們的程式碼,只要有語法上的錯誤,即會顯示紅色的線條,並在下方的PROBLEMS頁籤中,提示錯誤的原因。
6. Extensions(擴充套件)
VSCode有非常豐富的免費擴充套件,可以依個人喜好及需求進行安裝擴充,讓我們有更好的開發體驗。除了可以前往Visual Studio Code Marketplace安裝外,也可以直接在VSCode裡面進行安裝,這也就是接下來要教大家,如何在VSCode中安裝Python擴充套件,讓它變成我們開發Python的神器吧。

二、VSCode Python開發環境建置
Step1:開啟VSCode,點擊Extensions圖示,首先我們要來安裝Python套件,在搜尋的地方輸入【Python】。

Step2:選擇由Microsoft官方提供的版本,點擊【Install】進行安裝。

Step3:接下來安裝Code Runner套件(用來方便我們執行程式碼)。同樣於搜尋的地方輸入【Code Runner】,點擊【Install】進行安裝。

Step4:設定VSCode在儲存檔案的同時,自動幫我們依照PEP8原則排版程式碼。

在搜尋的地方輸入【python formatting】,就可以看到VSCode的排版採用autopep8。

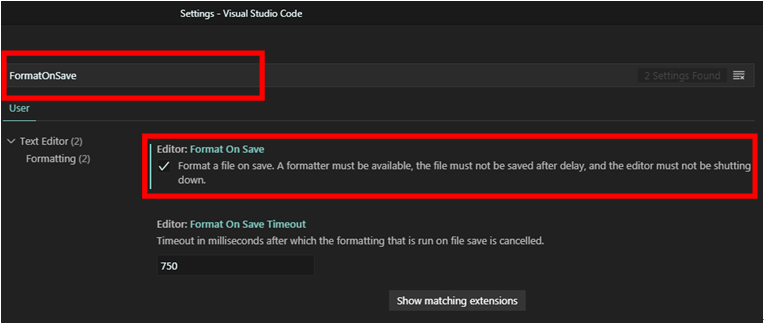
接著在搜尋的地方輸入【FormatOnSave】,勾選【Format a file on save】選項,讓VSCode在我們儲存檔案的時候,自動依照PEP8程式碼風格原則幫我們排版程式碼。
2020/12/16補充說明
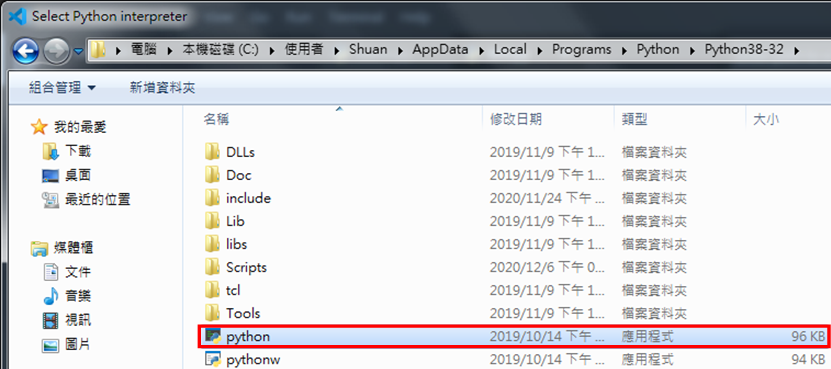
Step5:最後,在VSCode選擇Python的直譯器,也就是位於剛剛所安裝的Python路徑下。




三、小結
以上就是在VSCode中建置Python開發環境的方式,下一篇文章將會介紹Python變數及資料型態。若有其他疑問或說明不清楚的地方,歡迎與我分享!
如果您喜歡我的文章,請幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
如果您喜歡我的文章,請幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
有想要看的教學內容嗎?歡迎利用以下的Google表單讓我知道,將有機會成為教學文章,分享給大家😊
你可能有興趣的文章




感謝大大的文章~
回覆刪除不客氣,希望有幫助到您 :)
刪除請問安裝安VSCODE完成, 執行簡單的print指令, 但是output只有以下產出
回覆刪除[Running] python -u "c:\Users\kokola\Desktop\test\app.py"
[Done] exited with code=0 in 0.196 seconds
並沒有顯示結果, 是什麼地方設定錯了嗎?
toraman您好:
刪除可能您所要印出的Python內容並沒有正確指定,是否方便看一下您的程式碼呢?
謝謝 :)
只是網頁上簡單的內容. 謝謝
刪除title="Learn Code With Mike"
author="Mike"
print(title)
print(author)
toraman您好: 可能是VSCode沒有設定Python直譯器,已在文章中補充說明設定的方式(step5),請您試試看是否有辦法解決您的問題,如果還是無法,歡迎到Learn Code With Mike粉絲專頁私訊我,將會協助您解決,謝謝 :)
刪除python直譯器是哪個環節下載的?
回覆刪除我沒有找到...
您好,以下文章第三節所安裝的就是Python直譯器:
刪除https://www.learncodewithmike.com/2019/11/python46.html
而路徑位置也就是其中的step2,視窗中「INSTALL_NOW」下所顯示的路徑,請您再試試看 :)
感謝大大無私的分享貼文,幫助很大~
回覆刪除祝福平安喜樂=)
那個為什麼需要用到python執意氣呢? 裡面不是也可以打coding嗎?
回覆刪除[Done] exited with code=9009 in 0.372 seconds 請問上述問題如何解決,感謝
回覆刪除