
Photo by Christian Wiediger on Unsplash
Amazon相信大家都知道,是一個非常大的電商平台,同時,也提供了許多的雲端服務,常見的像儲存服務(S3)、虛擬伺服器(EC2)及運算服務(Lambda)等,讓全世界的開發人員,透過整合Amazon的雲端服務,來提升應用程式的彈性及效能。
所以本文以[Django教學9]6個步驟搞懂Django上傳圖片的功能部落格文章為基礎,分享如何將Django專案中的靜態檔案,如JavaScript、CSS及Image(圖片)檔等,儲存至Amazon S3服務,讓Django專案有較佳的儲存彈性,而不會隨著靜態檔案的增加,使得專案無限的擴張。其中的整合步驟包含:
- 建立Amazon S3 Bucket
- 建立Amazon IAM
- 安裝django-storages
- 儲存Django的上傳檔案到Amazon S3
- 儲存Django靜態檔案到Amazon S3
一、建立Amazon S3 Bucket
在開始進行實作前,需事先到AWS 管理主控台註冊帳號,首頁如下圖:
點擊「建立新帳戶」,按照步驟填寫相關資料即可。建立成功且登入後,就可以看到如下圖的畫面:

接著在「尋找服務」的地方就可以查詢所需的Amazon服務,所以輸入S3就可以找到,如下圖:

點擊後,會看到Amazon S3服務的首頁,可以進行相關的設定及操作。首先,要建立一個儲存體,就像儲存資料一定要先建立一個資料庫一樣,選擇「建立儲存體」,如下圖:
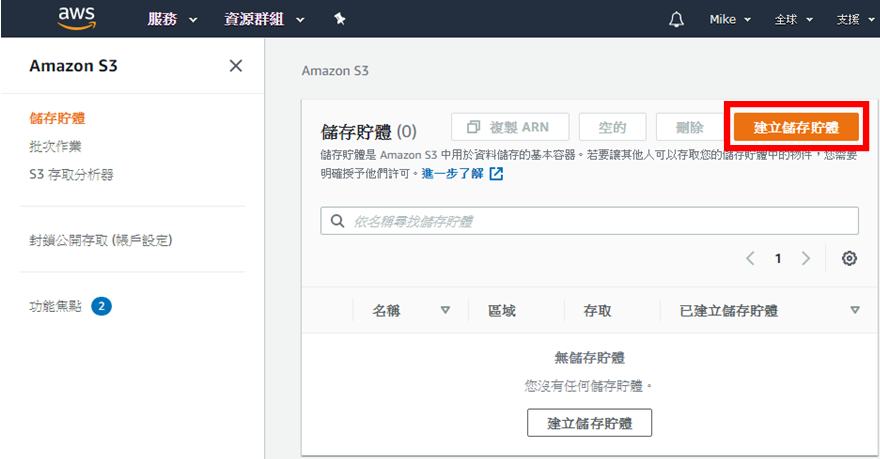
輸入儲存體的名稱及選擇「us-west-2」區域,剩下的保留預設值,點擊右下角的「建立儲存體」按鈕即可,如下圖:
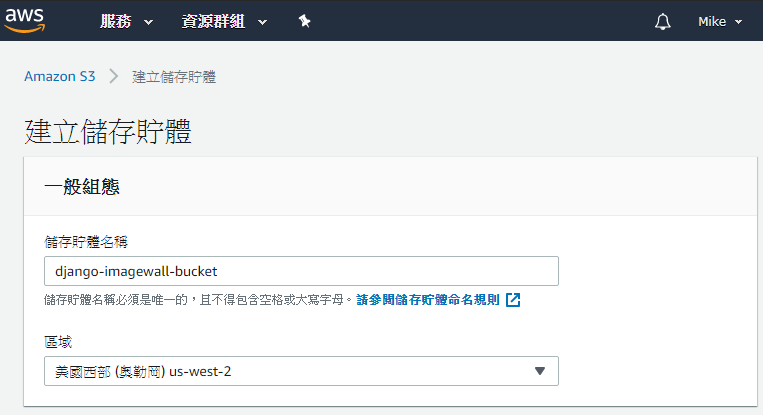
建立成功後,就可以在Amazon S3的首頁看到剛剛所建立的儲存體,如下圖:

接下來,就要設定這個Amazon S3儲存體的存取權限。點擊儲存體的名稱,並且切換到「許可」頁籤下的「CORS組態」,如下圖:
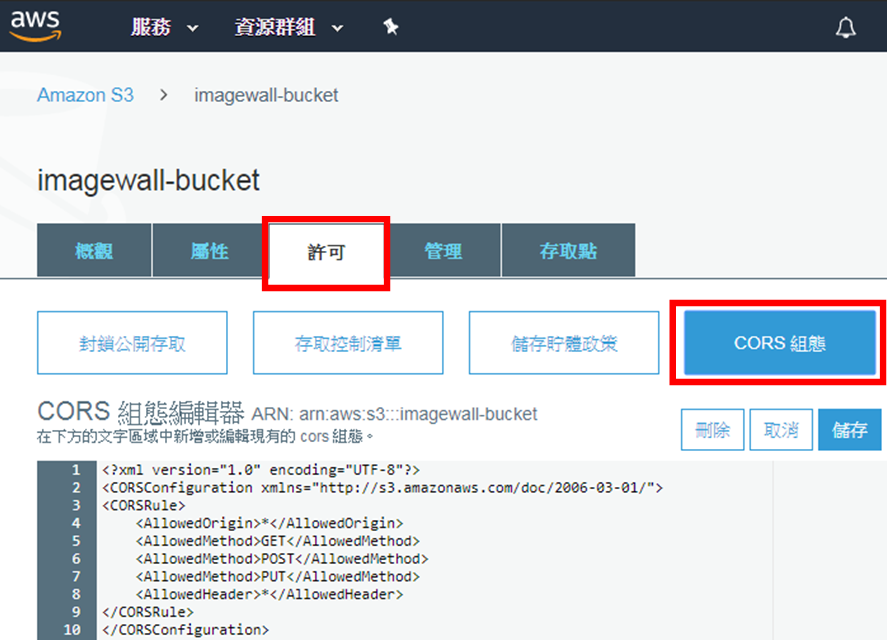
貼上範例中的以下CORS組態:
<?xml version="1.0" encoding="UTF-8"?>
<CORSConfiguration>
<CORSRule>
<AllowedOrigin>*</AllowedOrigin>
<AllowedMethod>GET</AllowedMethod>
<AllowedMethod>POST</AllowedMethod>
<AllowedMethod>PUT</AllowedMethod>
<AllowedHeader>*</AllowedHeader>
</CORSRule>
</CORSConfiguration>
其中的含義簡單來說,就是允許所有地區的使用者,透過GET、POST及PUT請求方法,來存取這個儲存體,也就是能夠查詢、新增及修改儲存體中的資料。詳細的設定方式可以參考Amazon的官方文件。
二、建立Amazon IAM
有了Amazon S3儲存體後,接著就要建立一個使用者來管理。回到Amazon管理主控台首頁,在「尋找服務」的地方輸入IAM,如下圖:

進入IAM(Identity and Access Management)的設定畫面後,選擇左側的「使用者」,並且點擊「新增使用者」按鈕,如下圖:
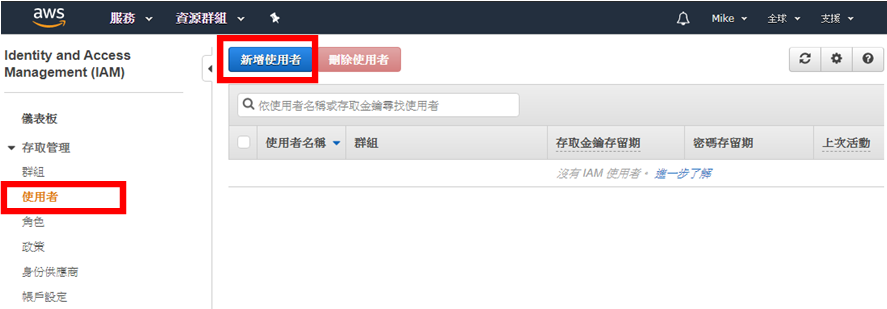
在第一步驟中輸入使用者的名稱及選擇存取類型,這邊勾選「程式設計方式存取」,也就是這個使用者需利用「存取金鑰ID」及「私密存取金鑰」來存取Amazon服務,如下圖:

接著,在第二步驟設定使用者所能存取的Amazon服務。切換到「直接連接現有政策」的頁籤下,輸入S3來進行查詢,並且勾選「AmazonS3FullAccess」,意思是這個使用者能夠利用第一步驟所選擇的存取類型來存取Amazon S3儲存體,如下圖:

之後的第三及第四步驟保留預設值即可,到第五步驟就可以看到Amazon提供給這個使用者專屬的「存取金鑰ID」及「私密存取金鑰」,如下圖:
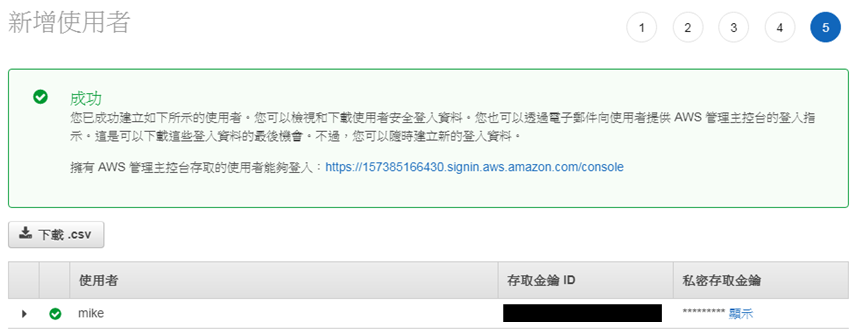
三、安裝django-storages
Amazon S3服務皆設定完成後,接下來就要安裝Django客製化後端儲存的套件django-storages,以及與Amazon S3服務協作的套件boto3,可以使用以下指令來進行安裝:
$ pip install django-storages
$ pip install boto3
安裝完成,開啟Django專案中的settings.py檔案,在INSTALL_APPS的地方,加上storages,如下範例:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'photos.apps.PhotosConfig',
'storages',
]
四、儲存Django的上傳檔案到Amazon S3
開啟Django專案中的settings.py檔案,增加Amazon S3服務的相關設定,包含「存取金鑰ID」、「私密存取金鑰」及「Amazon S3儲存體名稱」,如下範例:
#Amazon S3 Configuration
AWS_ACCESS_KEY_ID = '*****' #存取金鑰ID
AWS_SECRET_ACCESS_KEY = '*****' #私密存取金鑰
AWS_STORAGE_BUCKET_NAME = 'imagewall-bucket' #Amazon S3儲存體名稱
接著,增加Django Storages客製化後端儲存的設定,如下範例:
#Django Storages Configuration
AWS_S3_FILE_OVERWRITE = False #同名檔案是否要覆寫
AWS_DEFAULT_ACL = None
DEFAULT_FILE_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage' #上傳的媒體檔案
範例中的第4行設定,會將使用者所上傳的檔案,自動儲存至Amazon S3儲存體,而不會放置在Django專案中,所以在執行專案,並且上傳圖片後,在Chrome瀏覽器中點擊圖片右鍵,選擇檢查,就會看到圖片的來源為Amazon S3儲存體,如下圖:
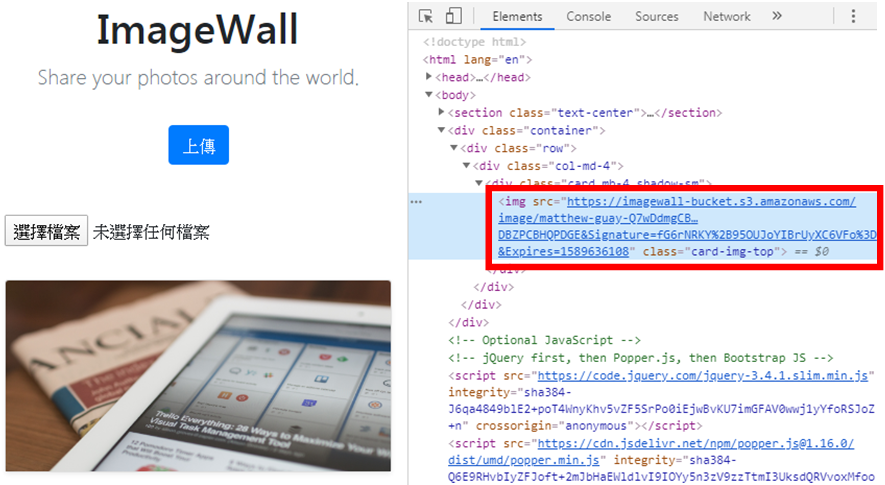
而在Amazon S3儲存體中,也可以看到成功的將使用者所上傳的圖片檔儲存起來,如下圖:

五、儲存Django靜態檔案到Amazon S3
除了可以將Django所上傳的檔案儲存到Amazon S3儲存體外,專案中的靜態檔案,像是JavaScript、Fonts及CSS檔等,也可以進行儲存。
首先,開啟Django專案的settings.py檔案,確認靜態檔案的路徑設定,如下範例:
STATIC_URL = '/static/'
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
接著,利用以下的指令,將Django專案中的靜態檔案收集至static資料夾中:
$ python manage.py collectstatic
執行結果
為了要告訴Django框架靜態檔案需讀取Amazon S3儲存體,所以在settings.py檔案中,再增加以下的設定:
STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage' # 靜態檔案的儲存
這時候執行專案,並且連線到Django Administration(管理員後台),就會發現板面的樣式都消失了,如下圖:

因為Django的靜態檔案已改為讀取Amazon S3儲存體,而Amazon S3儲存體中尚未有專案中的靜態檔案,所以,回到Amazon S3的專案儲存體中,點擊上傳的按鈕,如下圖:
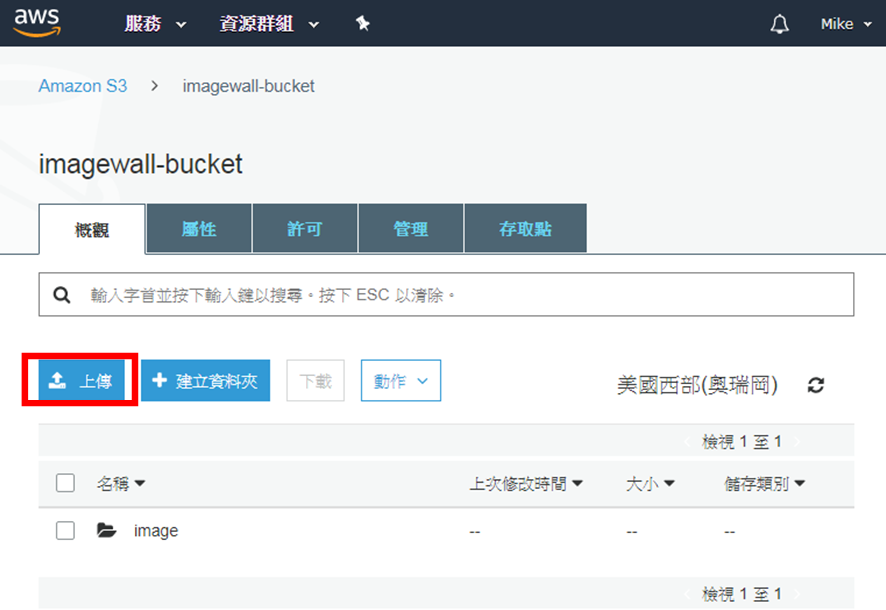
然後將Django專案中,將剛才在static資料夾下所收集的所有靜態檔案資料夾,拖拉至Amazon S3的上傳畫面中,如下圖:
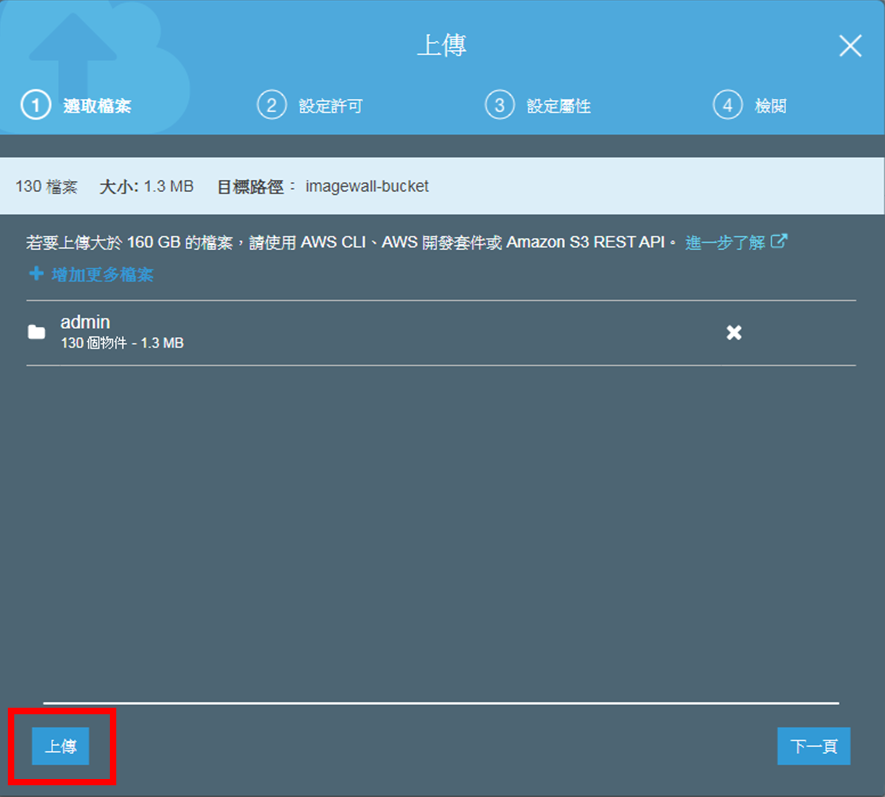
上傳成功後,Django專案中只要保留static資料夾,而它之下的靜態檔案資料夾,就可以進行刪除。
最後,重新啟動本地端伺服器,連線到Django Administration(管理員後台),板面的樣式就恢復正常了。
六、小結
透過本文的實作教學,Django專案就能成功的和Amazon S3服務進行整合,相較於儲存在Django專案中,提升了上傳檔案的儲存彈性,不會隨著檔案的增加,而難以管理及擴充。詳細的程式碼可以參考以下的GitHub連結,希望對於正在學習的你們,有所幫助。
有想要看的教學內容嗎?歡迎利用以下的Google表單讓我知道,將有機會成為教學文章,分享給大家😊




留言
張貼留言