
在海量的數據中,如果沒有進一步的探索與分析,往往無法看出其中所傳達的訊息,而使用Pandas套件的Pivot Table樞紐分析表,就能夠將欄位資料透過交叉比對的方式,進行群組、匯總及統計,幫助資料分析人員快速解讀資料。
本文就以Kaggle網站的2017年Stack Overflow開發者調查資料集(survey_results_public.csv)為例,帶大家瞭解Pandas套件的Pivot Table樞紐分析表使用方式,包含:
- Pandas Pivot Table建立方式
- Pandas Pivot Table自訂統計方法
- Pandas Pivot Table填補遺漏值
- Pandas Pivot Table小計及總計
一、Pandas Pivot Table建立方式
首先,來看一下Kaggle網站的2017年Stack Overflow開發者調查資料集(survey_results_public.csv)的內容,如下範例:
import pandas as pd
df = pd.read_csv('survey_results_public.csv')
print(df)截取部分執行結果

import pandas as pd
df = pd.read_csv('survey_results_public.csv',
usecols=['FormalEducation', 'YearsCodedJob', 'Salary'])
print(df)執行結果

import pandas as pd
df = pd.read_csv('survey_results_public.csv',
usecols=['FormalEducation', 'YearsCodedJob', 'Salary'])
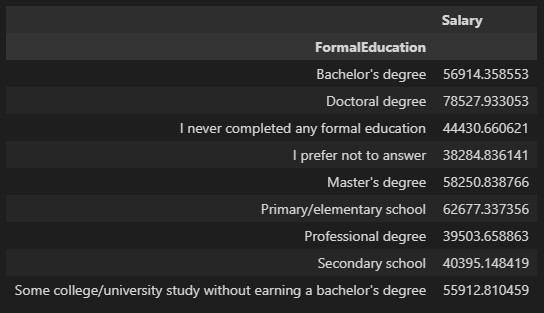
pvt = df.pivot_table(values='Salary', index='FormalEducation')
print(pvt)執行結果
二、Pandas Pivot Table自訂統計方法
當然,在資料分析的過程中,不會只有計算平均值,如果想要自訂其它的統計方法,可以透過pivot_table()方法(Method)的aggfunc關鍵字參數來指定統計函式,如下範例:
import pandas as pd
import numpy as np
df = pd.read_csv('survey_results_public.csv',
usecols=['FormalEducation', 'YearsCodedJob', 'Salary'])
pvt = df.pivot_table(values='Salary',
index='FormalEducation',
aggfunc=np.median)
print(pvt)執行結果

而同時需要多個統計方法時,在pivot_table()方法(Method)的aggfunc關鍵字參數中,用串列(List)的方式來指定即可,如下範例:
import pandas as pd
import numpy as np
df = pd.read_csv('survey_results_public.csv',
usecols=['FormalEducation', 'YearsCodedJob', 'Salary'])
pvt = df.pivot_table(values='Salary',
index='FormalEducation',
aggfunc=[np.mean, np.median])
print(pvt)執行結果

三、Pandas Pivot Table填補遺漏值
如果想要分析各個正規教育(FormalEducation)的程式工作年資(YearsCodedJob)平均薪水,這時候,就需要在pivot_table()方法(Method)設定columns關鍵字參數,如下範例:
import pandas as pd
import numpy as np
df = pd.read_csv('survey_results_public.csv',
usecols=['FormalEducation', 'YearsCodedJob', 'Salary'])
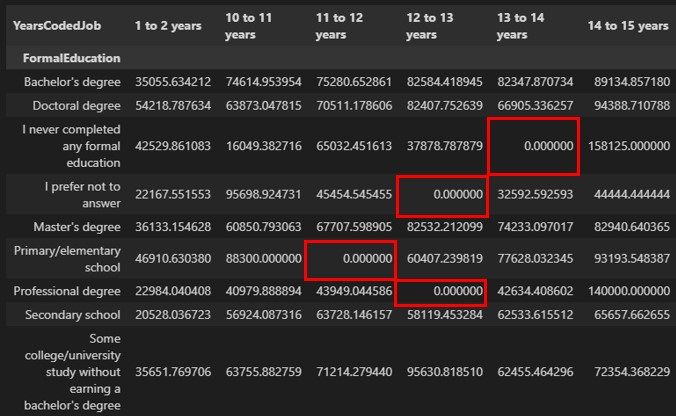
pvt = df.pivot_table(values='Salary',
index='FormalEducation',
columns='YearsCodedJob')
print(pvt)截取部分執行結果

import pandas as pd
import numpy as np
df = pd.read_csv('survey_results_public.csv',
usecols=['FormalEducation', 'YearsCodedJob', 'Salary'])
pvt = df.pivot_table(values='Salary',
index='FormalEducation',
columns='YearsCodedJob',
fill_value=0)
print(pvt)截取部分執行結果
四、Pandas Pivot Table小計及總計
最後,計算每列與每欄資料的「平均小計」及「平均總計」,只需設定pivot_table()方法(Method)的margins關鍵字參數為True即可,如下範例:
import pandas as pd
import numpy as np
df = pd.read_csv('survey_results_public.csv',
usecols=['FormalEducation', 'YearsCodedJob', 'Salary'])
pvt = df.pivot_table(values='Salary',
index='FormalEducation',
columns='YearsCodedJob',
fill_value=0,
margins=True)
print(pvt)執行結果

五、小結
在進行資料統計分析,Pandas套件的Pivot Table樞紐分析表可以說是非常好用的工具之一,可以快速解讀欄位資料之間的關係,找出其中的含意,並且和Excel中的樞紐分析表相似,很容易上手,希望有幫助大家學會Pandas套件的Pivot Table樞紐分析表應用方式。
本文是筆者Mike在DataCamp平台上所學到的Pandas套件資料清理技巧,加以應用和大家分享。DataCamp平台上有非常多與資料科學、分析有關的教學,包含資料視覺化、清理、機器學習等,並且有專家帶領你完成資料分析專案,大家有興趣的話,可以加入DataCamp平台一起學習唷。
如果喜歡我的文章,別忘了在下面訂閱本網站,以及幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
- [Pandas教學]你要學會的Pandas套件對於資料單位與格式的處理技巧
- [Pandas教學]解密Pandas套件清理類別資料(Categorical Data)的方法
- [Pandas教學]3個實用的Pandas套件清理重複資料教學
- [Pandas教學]善用Pandas套件幫你清理資料範圍異常的資料
- [Pandas教學]教你用Pandas套件清理資料中的常見資料型態問題
- [Pandas教學]4個必學的Pandas套件處理遺漏值(Missing Value)資料方法
- [Pandas教學]快速掌握Pandas套件讀寫SQLite資料庫的重要方法
- [Pandas教學]善用Pandas套件的Groupby與Aggregate方法提升資料解讀效率
- [Pandas教學]資料視覺化必懂的Pandas套件繪製Matplotlib分析圖表實戰
- 解析Python網頁爬蟲如何有效整合Pandas套件提升資料處理效率




留言
張貼留言