
Photo by Sincerely Media on Unsplash
在Python變數與資料型態文章中,說明到字串的表示法為文字前後加上單引號或雙引號,使用單引號或雙引號依個人喜好選擇,大部分習慣上使用雙引號。本篇將介紹Python String(字串)資料型態的基本用法,包含字串的合併、格式化、裁切及常用的內建方法(Built-in function)。一、字串連接(String concatenating)

二、字串格式化(String formatting)
二、字串格式化(String formatting)
在Python3中,提供了簡潔的字串格式化語法,來達到跟上面範例相同的效果。使用方式就是在字串的前方加上f 或 F 前綴字,接著在 {} 符號中,傳入變數或運算式,Python會將 {} 中的變數資料或運算結果帶出來。

三、字串裁切(String slicing)
三、字串裁切(String slicing)
字串裁切就是基於原字串取出想要的部分,像是想存取字串中特定位置的字元,在Python中使用 [] 符號,並傳入索引值。特別注意索引值由0開始計算。
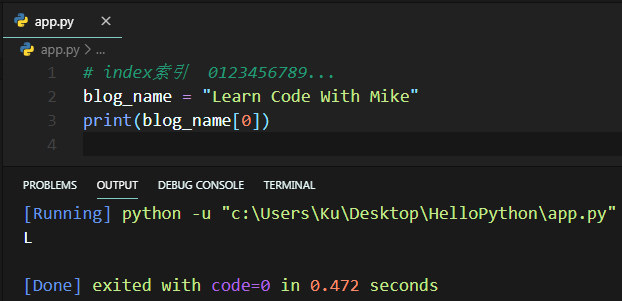



相反的,起始索引未輸入,Python預設會填入0。


四、常用的字串內建方法(Built-in function)
四、常用的字串內建方法(Built-in function)
什麼是方法(function)呢?簡單來說,就是封裝了專們執行某項任務的可重複使用程式碼。舉例來說,洗衣機包含了很多顆功能按鈕,一顆按鈕就是代表一個功能(function),專門執行某項任務(例如:脫水)。本篇就來介紹幾個Python 字串資料型態常用的內建方法(Built-in function)。
1. upper():將字串轉為大寫字母。
 2. lower():將字串轉為小寫字母。
2. lower():將字串轉為小寫字母。
 3. capitalize():將字串的首字轉為大寫字母。
3. capitalize():將字串的首字轉為大寫字母。
 4. title():將字串中的每個單字字首轉為大寫字母。
4. title():將字串中的每個單字字首轉為大寫字母。
 5. len():取得字串的文字總數。
5. len():取得字串的文字總數。
 6. strip():清除字串的前後空白。
6. strip():清除字串的前後空白。

7. input():取得使用者輸入的資料。







我們可以看到輸出結果的第一個為原字串,前後包含了許多空白,第二個字串為呼叫strip()方法後清除前空白的結果。
7. input():取得使用者輸入的資料。

這邊要說明一個觀念,input()方法取得使用者輸入的資料皆為字串資料型態,就算是輸入數字也是字串資料型態。以下範例中的type()方法將會於下一篇文章中介紹其使用的方式及時機。

五、小結
五、小結
以上就是Python String(字串)的介紹,下一篇文章將會介紹Python數值與型別轉換。若有其他疑問或說明不清楚的地方,歡迎與我分享!
有想要看的教學內容嗎?歡迎利用以下的Google表單讓我知道,將有機會成為教學文章,分享給大家😊
你可能有興趣的文章




留言
張貼留言