
Photo by chuttersnap on Unsplash
在這邊鼓勵大家在看部落格的同時,可以打開自己的開發工具練習,這樣可以增加對Python的熟悉度唷。Python開發環境的建置可以參考Visual Studio Code Python環境建置文章,準備好了嗎,讓我們進入今天的主題吧。Tuples(元組)是Python另一個資料型態,它和List(串列)一樣是一個容器,能夠存放多個不同資料型態的資料(元素),同樣以逗號區隔,但是是以 () 符號將所有元素括起來,我們來看它的表示方式:
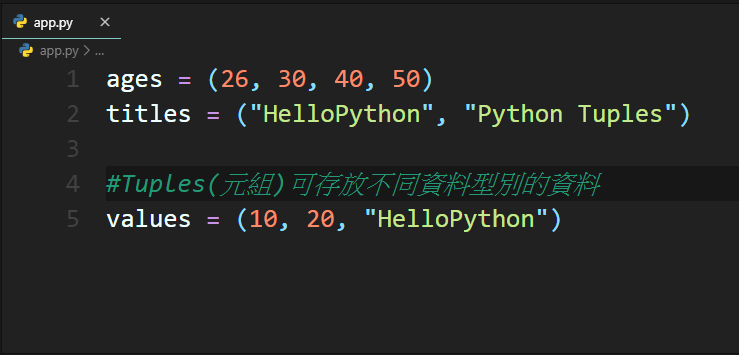
Tuples(元組)有幾個特性:
- Iterable(可疊代的):和List(串列)一樣,可以透過Python迴圈來進行讀取。
- Unmodifiable(不可修改的):這個特性是Tuples(元組)和List(串列)最大的不同,Tuples(元組)中的元素不可修改,只能唯讀,所以它不像List(串列)有任何可以修改元素的方法(Method),像是新增、修改及刪除元素。
也由於Tuples(元組)只能唯讀,不能修改元素,所以Tuples(元組)主要應用的情境在於防止資料被意外的修改。舉例來說,在一個應用程式中,可能有一些資料在運算的過程中,想防止不小心的被修改到,這時候就可以使用Tuples(元組)來存放那些資料。
本篇文章就來介紹Python
Tuples(元組)的基本操作,包含:
- 建立Tuples的方法
- 存取Tuples元素的方法
- 尋找Tuples元素的方法
一、建立Tuples的方法
1. 於 () 符號中輸入資料,並且以逗號區隔。
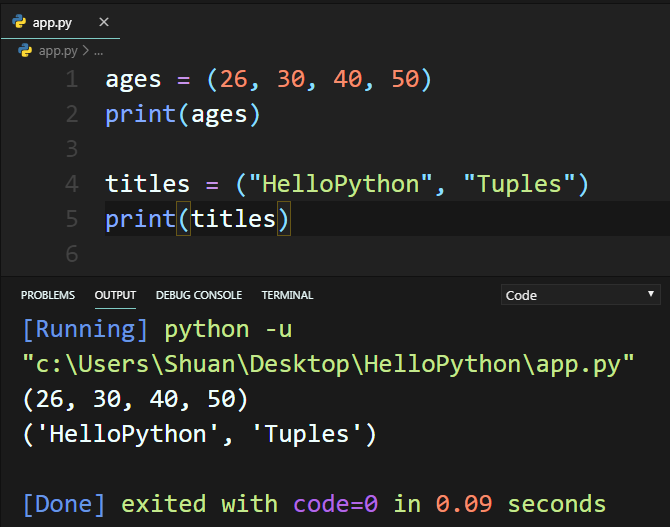
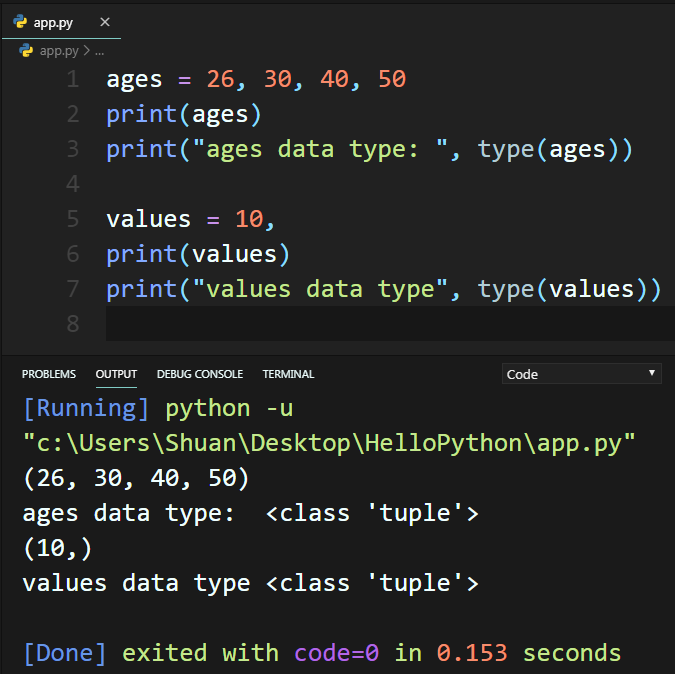
2. 不加 () 符號,直接指派資料,並且以逗號區隔,Python會預設為Tuples(元組)資料型態,不過要注意的是如果只有一個資料,一定要再加一個逗號。
3. 使用tuple()方法,傳入Iterable(可疊代的)物件來建立Tuples(元組)。

4. 使用 * 符號來建立Tuples(元組)。
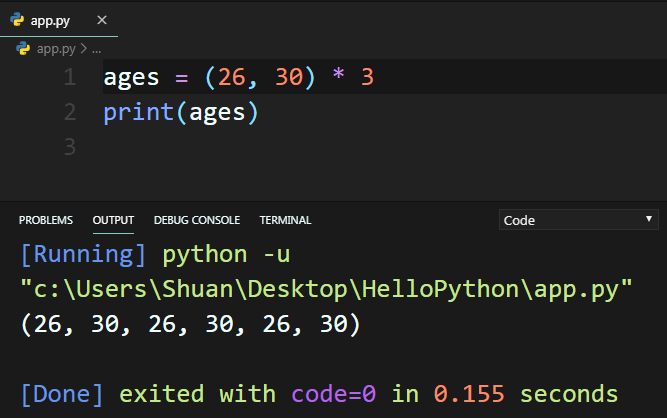
二、存取Tuples元素的方法

2. 如果想取得特定範圍的Tuples(元組)元素,使用 [:] 符號並傳入索引值。
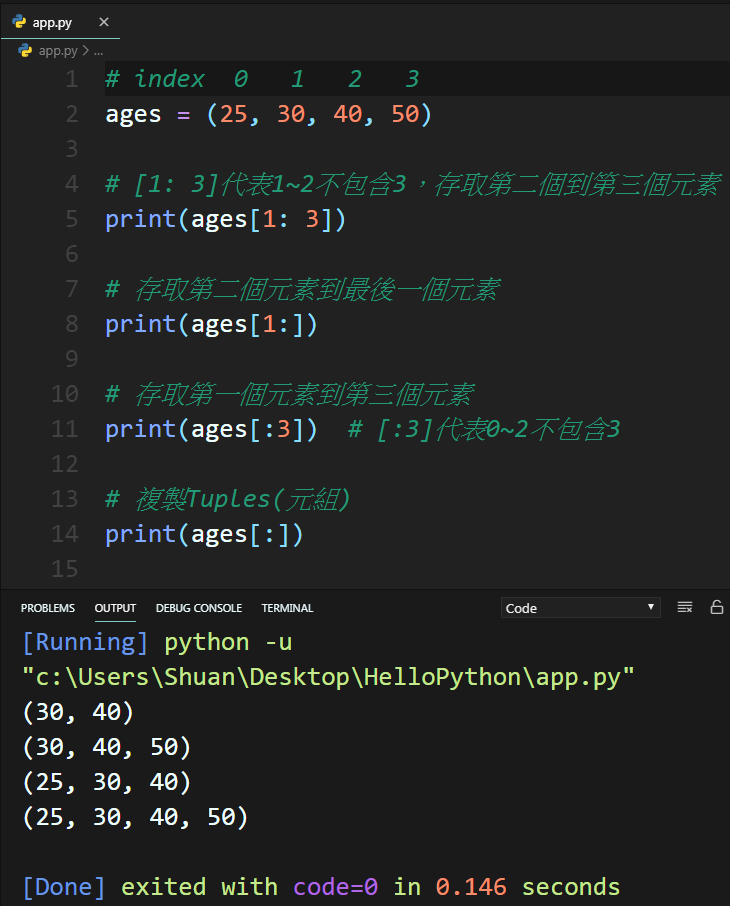
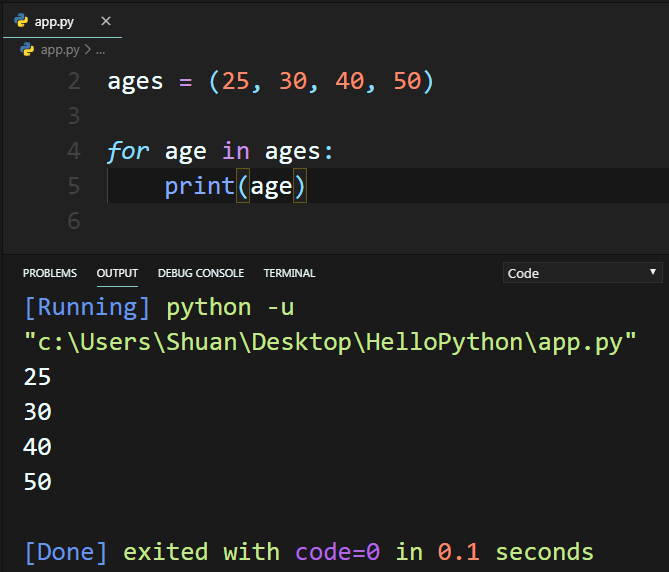
三、尋找Tuples元素的方法
1. 可以使用index()方法,將要尋找的Tuples元素傳入,來取得該元素的索引值。


2. 可以使用count()方法,將要尋找的Tuples元素傳入,來取得該元素在Tuples中的個數。
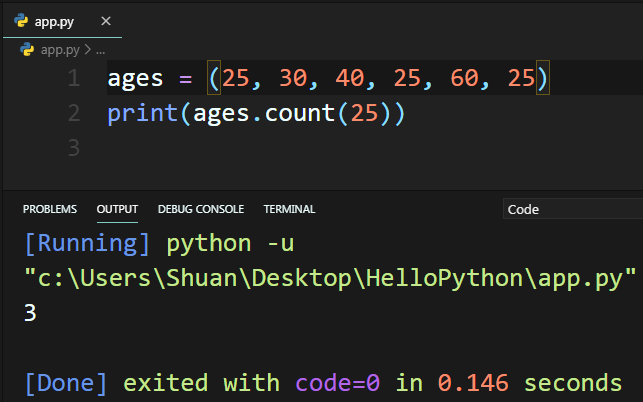
四、小結
以上就是Python Tuples(元組)的介紹,若有其他疑問或說明不清楚的地方,歡迎與我分享!
如果您喜歡我的文章,請幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
如果您喜歡我的文章,請幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。




感謝分享教學,受益頗豐
回覆刪除感謝您的支持,後續會持續推出Python教學文章,大家互相交流分享吧 :)
刪除Hi Mike,
回覆刪除因為在List跟Tuples這兩篇都看到,所以想確認一下:if後面不用加else嗎?
我試著跟你打一樣的,結果少了else的話,無論if判斷為True或False,都會執行耶。
Mabelle您好,您的問題非常好,本文最後一行的程式碼的確不管True或False都會執行,因為程式碼是由上而下執行,當if成立,就會執行其中的內容,並且繼續往下執行,反之,if不成立,其中的內容就不會執行,但是,還是會繼續往下執行if之後的程式碼,所以最後一行不管if有沒有成立都會執行。
刪除為了避免學習的困擾,已更新範例的內容,另外,if後面不一定要加else,視需求而定,如果只是單純判斷某一個邏輯是否成立,而之後的程式碼不管怎麼樣都要執行,則可以不需要加else。
希望以上有解答您的疑惑,感謝您的提問 :)
了解,謝謝你的回答,Mike~ ^_^
回覆刪除