
Photo by Matthew Guay on Unsplash
大家在使用Python的Django框架來建置網站時,預設會提供SQLite輕量資料庫來進行開發,通常適用在規模不大的小型應用程式上,但是,隨著網站功能的擴大或用戶數的增加,就會需要使用像PostgreSQL、MariaDB、MySQL及Oracle等企業級的資料庫,來提升資料的存取效能,好消息是,這四家資料庫Django官方皆有支援。
所以本文將以PostgreSQL資料庫,來示範如何在Django框架中,將預設連接的SQLite資料庫,改為PostgreSQL資料庫,讓Django所建置出來的網站,能有較佳的資料處理。其中主要的步驟包含:
- 安裝PostgreSQL
- 建立PostgreSQL資料庫
- 設定Django連接PostgreSQL
一、安裝PostgreSQL
首先,前往PostgreSQL官方下載網站,如下圖:

依照作業系統來下載安裝檔即可,本文將以Windows作業系統為例進行說明。開啟安裝檔後,可以看到如下圖的畫面:

安裝過程基本上都保留預設值,並且下一步就好。其中,有一個步驟會需要設定PostgreSQL的密碼,如下圖:
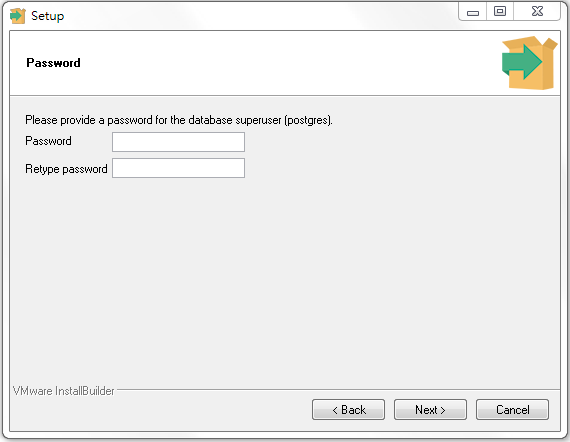
設定完成,點擊下一步來設定Port號,這邊同樣保留預設值,如下圖:
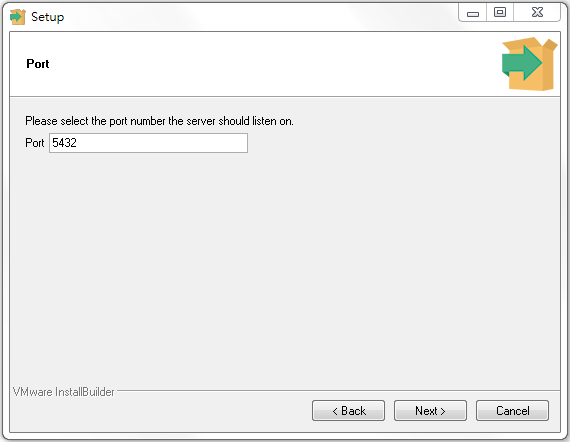
經過一段時間的安裝後,會看到設定完成的畫面,如下圖:
點擊Finish,接著在下拉選單中選擇PostgreSQL,如下圖:
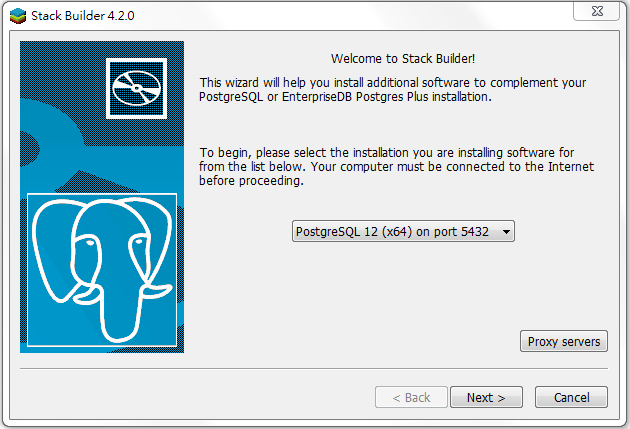
點擊下一步,在Database Server的地方,選擇最新版的PostgreSQL資料庫伺服器,如下圖:
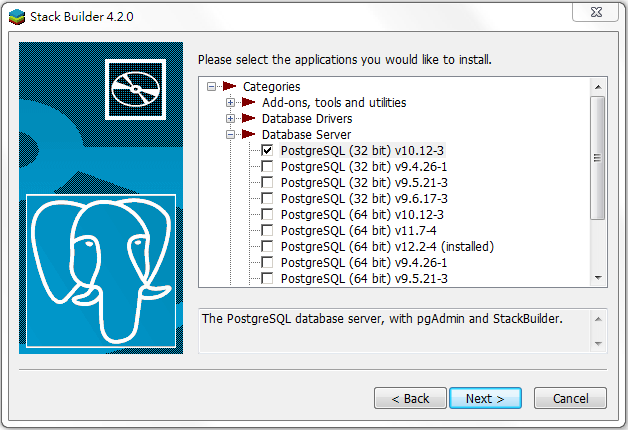
最後,勾選Skip Installation,如下圖:
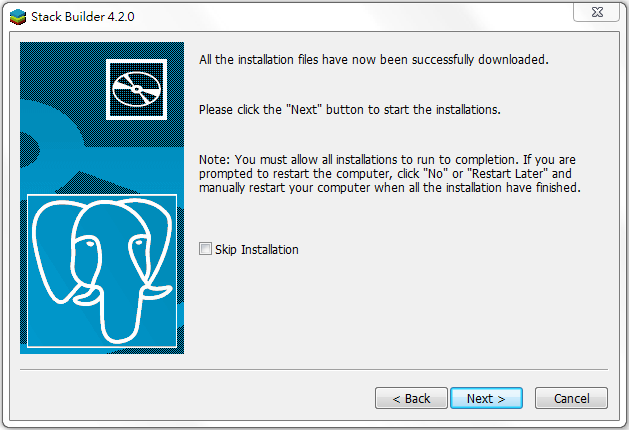
接著,點擊Finish就完成PostgreSQL的安裝了。
二、建立PostgreSQL資料庫
PostgreSQL安裝完成後,接下來就可以為Django專案建立資料庫,來儲存專案所需的資料。
在剛剛的PostgreSQL安裝過程中,有幫我們安裝了一個pgAdmin工具,讓開發人員能夠有效率的進行PostgreSQL資料庫操作。
開啟的方式除了在Windows開始的地方搜尋pgAdmin關鍵字外,也可以在安裝目錄下(C:\Program Files\PostgreSQL\12\pgAdmin 4\bin),找到pgAdmin4的執行檔。
開啟後,pgAdmin會要求輸入剛剛所設定的PostgreSQL密碼,登入成功就可以看到如下畫面:

在PostgreSQL資料庫的架構中,第一層為Server Group(伺服器群組),在它下面可以有多個Server(伺服器),而在Server(伺服器)之下則可以擁有多個資料庫。
有了以上的概念後,就可以知道在建立PostgreSQL資料庫前,需要先建立一個Server Group(伺服器群組),如下圖:
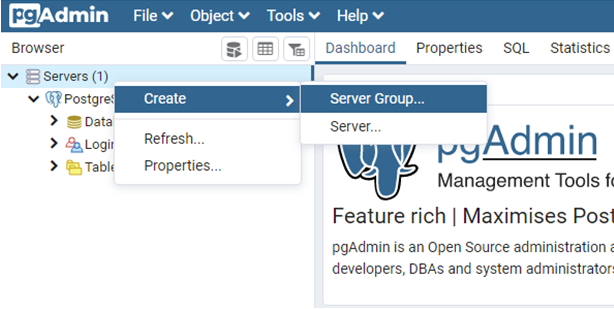
在跳出的視窗中,輸入自訂的Server Group(伺服器群組)名稱即可。接著,在自訂的Server Group(伺服器群組)下新增一個Server(伺服器),如下圖:
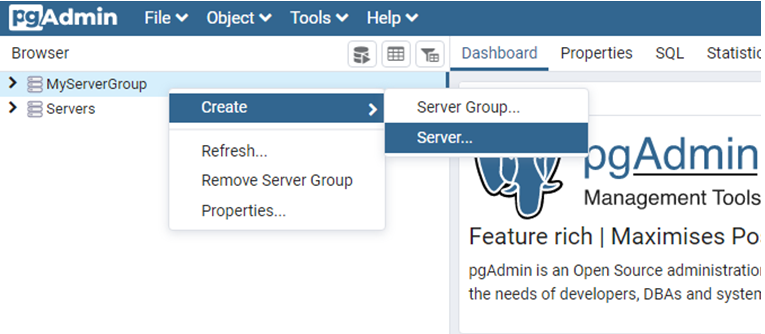
這時候,就需要自訂Server(伺服器)的名稱,如下圖:
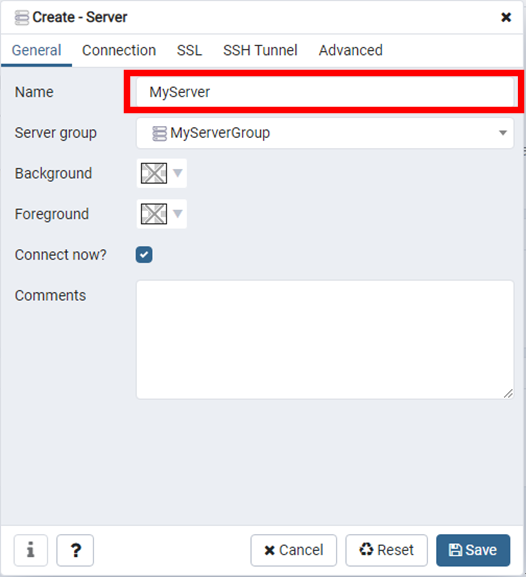
以及Server(伺服器)的位址及密碼。由於本文是在本地端執行,所以在Server(伺服器)位址的地方為localhost,如下圖:
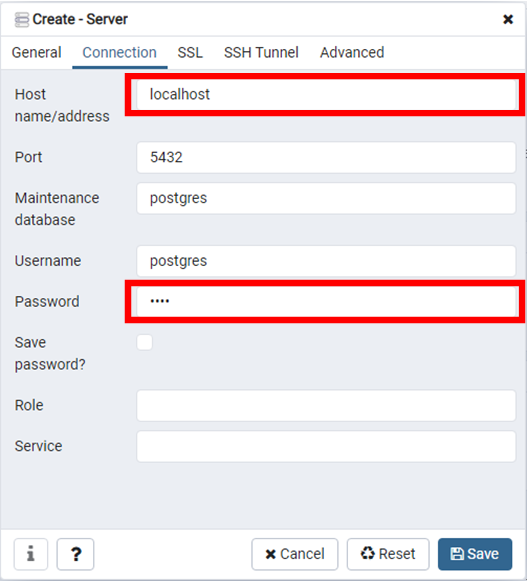
有了Server(伺服器)後,就可以在它下面建立資料庫,如下圖:
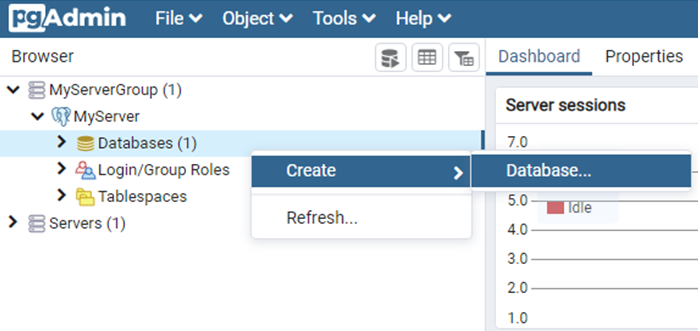
在跳出的視窗中,輸入資料庫名稱,儲存即可。完成的PostgreSQL架構如下圖:

三、設定Django連接PostgreSQL
PostgreSQL資料庫建置完成,接下來,利用以下指令安裝psycopg2套件,讓Python的應用程式能夠與PostgreSQL資料庫進行溝通。
$ pip install psycopg2
安裝完成後,開啟Django專案中的settings.py檔案,在DATABASES的地方,將原SQLite資料庫修改為以下的PostgreSQL設定:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql', #PostgreSQL
'NAME': 'BOOKSTORE', #資料庫名稱
'USER': 'postgres', #資料庫帳號
'PASSWORD': '****', #資料庫密碼
'HOST': 'localhost', #Server(伺服器)位址
'PORT': '5432' #PostgreSQL Port號
}
}
接著,就可以執行以下的Django Migration(資料遷移)指令,將Django Model中的資料模型同步至PostgreSQL資料庫中。
$ python manage.py migrate
最後,開啟pgAdmin工具,在剛才自訂的PostgreSQL資料庫中,即可看到Django專案同步過來的資料表,如下圖:
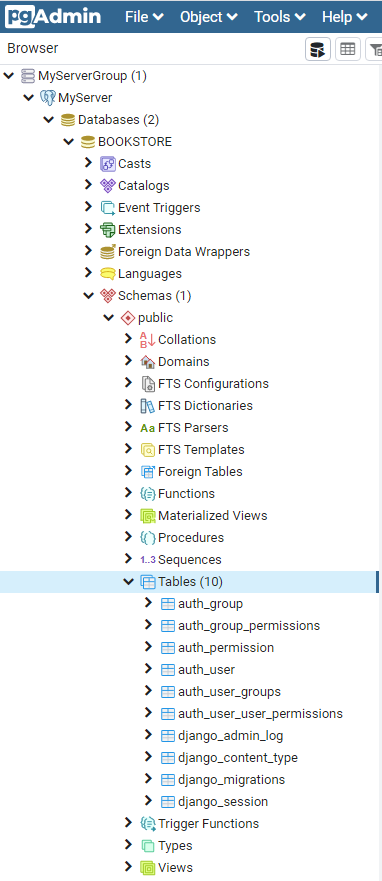
四、小結
以上就是Django專案連接PostgreSQL資料庫的詳細過程,除此之外,也讓大家瞭解在Django專案中是如何進行不同資料庫的設定,希望對於正在學習的朋友們有所幫助。如果在練習的過程中,有遇到任何問題,歡迎留言提問,我將盡力為各位解答。




您好, 執行後出現 Server Error(500) 請問要怎麼處理. 謝謝
回覆刪除