
Photo by Alvaro Reyes on Unsplash
LINE Bot的自動化回覆訊息特性,使得被廣泛的應用在許多的場景,其中又以推播有價值的資訊為大宗,而這些資料除了可以像[Python+LINE Bot教學]建構具網頁爬蟲功能的LINE Bot機器人文章一樣,利用網路爬蟲即時蒐集外,當資料量非常大或有歷史資料的查詢需求時,也可以將資料儲存至資料庫中,使用者需要時,LINE Bot直接從資料庫中取得即可,提升執行效能。
所以本文將以旅遊景點機器人為例,分享LINE Bot如何讀取PostgreSQL資料庫中的資料,提供給使用者。執行架構如下圖:
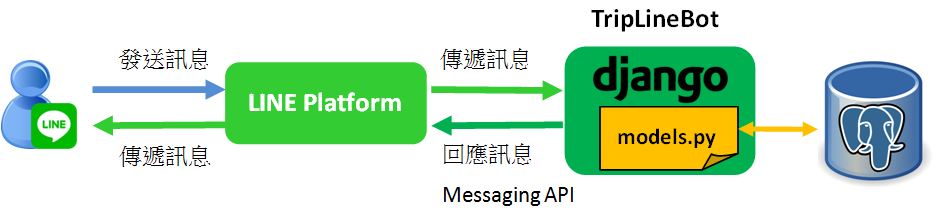
上圖中當使用者發送旅遊地區給LINE Bot時,它就會查詢PostgreSQL資料庫中該地區的景點資料,回覆給使用者。其中的實作重點包含:
- 建立LINE Bot
- 建立PostgreSQL資料庫
- LINE Bot連接PostgreSQL
- LINE Bot查詢PostgreSQL
- LINE 設定Webhook URL
一、建立LINE Bot
在[Python+LINE Bot教學]6步驟快速上手LINE Bot機器人文章中,介紹到建立LINE Bot有三個步驟,分別為「建立服務提供者(Provider)」、「建立頻道(Channel)」及「連結應用程式(APP)」,所以,首先需建立服務提供者(Provider),讓LINE官方知道這個LINE Bot是誰提供的,如下圖:


選擇後,填寫LINE Bot頻道(Channel)的基本資料,如下圖:


填寫完成點擊「Create」按鈕,LINE平台就會產生專屬於這個LINE Bot的連結資訊,包含:
- Channel secret(頻道密碼):位於Basic settings頁籤中,如下圖:

- Channel access token(頻道憑證):位於Messaging API頁籤中,要按下右方的「Issue」按鈕才會出現,如下圖:

最後,就是要利用這兩個資訊來連結應用程式(APP),這個應用程式(APP)也就是接收使用者發送的訊息、執行商業邏輯及回覆訊息的地方。
本文將以Django框架來建置LINE Bot應用程式(APP),首先,利用以下的指令來進行安裝:
$ pip install django
接著,安裝line-bot-sdk套件,用來操作LINE的Messaging API,回覆使用者訊息,如下:
$ pip install line-bot-sdk
安裝完成後,利用以下的指令建立Django專案(bot)及應用程式(triplinebot):
$ django-admin startproject bot . $ python manage.py startapp triplinebot
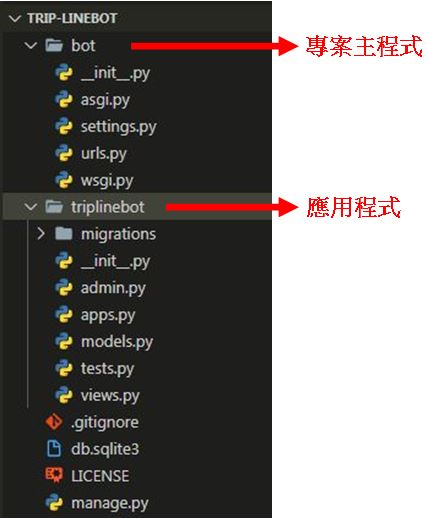
使用Visual Studio Code開啟專案,就可以看到目前的專案架構如下圖:
接下來,開啟專案主程式(bot)下的settings.py設定檔,加入應用程式(triplinebot),如下範例:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'triplinebot.apps.TriplinebotConfig',
]並且,新增剛剛所取得的兩個LINE Bot連結資訊,如下範例:
LINE_CHANNEL_ACCESS_TOKEN = 'Messaging API的Channel access token' LINE_CHANNEL_SECRET = 'Basic settings的Channel Secret'
到這邊與LINE Bot應用程式的連結就設定完成了。
二、建立PostgreSQL資料庫
要讓LINE Bot讀取PostgreSQL資料庫,就需要先進行資料庫安裝的動作,可以參考[Django教學15]Django連接PostgreSQL資料庫手把手教學文章的第一節安裝步驟。
接著,開啟PostgreSQL資料庫,在Windows作業系統上,可以在開始的地方搜尋pgAdmin關鍵字或前往安裝路徑(C:\Program Files\PostgreSQL\12\pgAdmin 4\bin),開啟pgAdmin4的執行檔。登入後,可以看到如下圖的畫面:

由於PostgreSQL資料庫為階層式的結構,由上到下依序為伺服器群組(Server Group)、伺服器(Server)與資料庫(Database),所以要建立資料庫(Database),就需要從上到下依序建立。首先,點擊右鍵,選擇建立伺服器群組(Server Group),如下圖:
接著,建立伺服器(Server),在General(一般資訊)的地方輸入名稱,如下圖:
並且,在旁邊的Connection(連線資訊)輸入Server(伺服器)的位址及密碼。由於本文是在本地端執行,所以Server(伺服器)位址為localhost,如下圖:
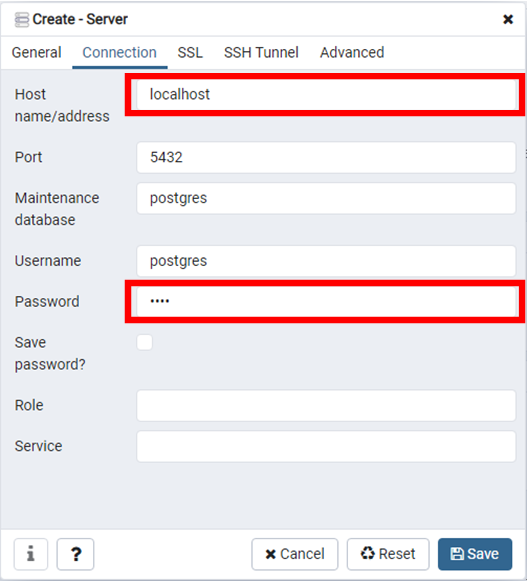
有了Server(伺服器)後,就可以在它下面建立資料庫(Database),如下圖:
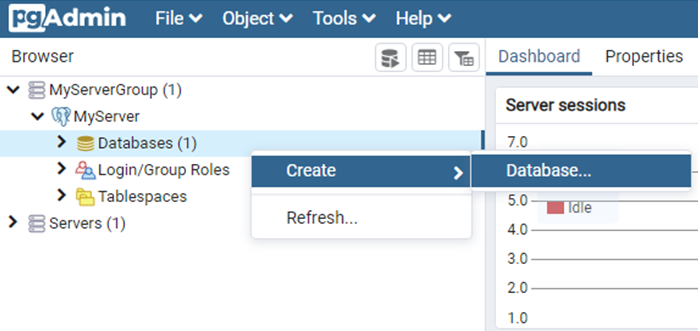
在跳出的視窗中,輸入資料庫名稱(TRIP),儲存即可。完成的PostgreSQL架構如下圖:

三、LINE Bot連接PostgreSQL
LINE Bot及PostgreSQL資料庫都建置完成後,接下來就要將它們進行連接,而要讓Python所建構的專案能夠與PostgreSQL資料庫進行連接,需要安裝psycopg2套件,如下:
$ pip install psycopg2一般情況下,Django專案預設連接的資料庫為SQLite資料庫,如果想要更換其它的資料庫,像本文所使用的是PostgreSQL資料庫,可以修改settings.py檔案中,DATABASES的設定:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql', #PostgreSQL
'NAME': 'TRIP', #資料庫名稱
'USER': 'postgres', #資料庫帳號
'PASSWORD': '****', #資料庫密碼
'HOST': 'localhost', #Server(伺服器)位址
'PORT': '5432' #PostgreSQL Port號
}
}設定完成,LINE Bot就能夠連結PostgreSQL資料庫,這時候,就可以開啟Django應用程式(triplinebot)下的models.py檔案,設計LINE Bot所需要使用的資料表(Table)欄位,如下範例:
from django.db import models
class Location(models.Model):
area = models.CharField(max_length=20) # 地區
name = models.CharField(max_length=100) # 景點名稱
address = models.CharField(max_length=500) # 地址接著,利用以下的指令執行Migration(資料遷移),將Django專案中所設計的Model(資料模型)同步到資料庫中:
$ python manage.py makemigrations $ python manage.py migrate
開啟PostgreSQL資料庫,就可以看到Django專案的Model(資料模型)已同步到資料庫中,如下圖:

四、LINE Bot查詢PostgreSQL
接下來,就在triplinebot_location資料表中新增幾筆資料,讓LINE Bot能夠進行查詢。點擊右鍵,選擇「Query Tool(查詢工具)」,如下圖:
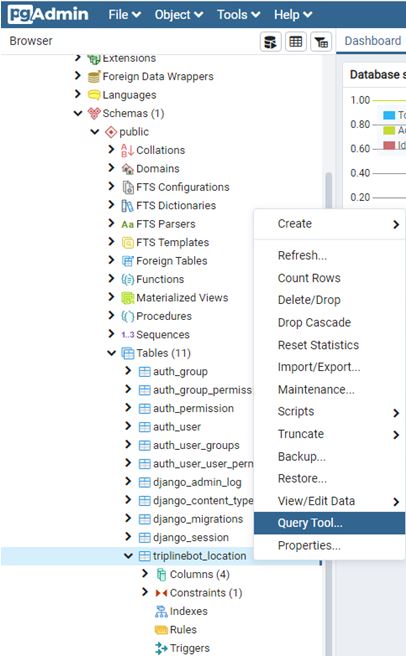


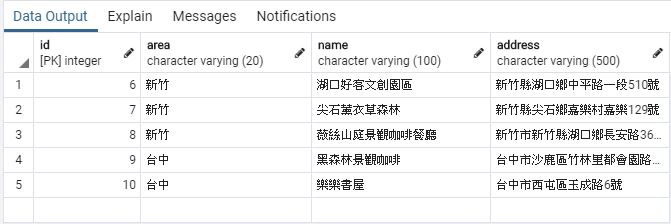
from django.shortcuts import render
from django.http import HttpResponse, HttpResponseBadRequest, HttpResponseForbidden
from django.views.decorators.csrf import csrf_exempt
from django.conf import settings
from .models import Location
from linebot import LineBotApi, WebhookParser
from linebot.exceptions import InvalidSignatureError, LineBotApiError
from linebot.models import MessageEvent, TextSendMessage
line_bot_api = LineBotApi(settings.LINE_CHANNEL_ACCESS_TOKEN)
parser = WebhookParser(settings.LINE_CHANNEL_SECRET)
@csrf_exempt
def callback(request):
if request.method == 'POST':
signature = request.META['HTTP_X_LINE_SIGNATURE']
body = request.body.decode('utf-8')
try:
events = parser.parse(body, signature) # 傳入的事件
except InvalidSignatureError:
return HttpResponseForbidden()
except LineBotApiError:
return HttpResponseBadRequest()
for event in events:
if isinstance(event, MessageEvent): # 如果有訊息事件
# 篩選location資料表中,地區欄位為使用者發送地區的景點資料
locations = Location.objects.filter(area=event.message.text)
content = '' # 回覆使用者的內容
for location in locations:
content += location.name + '\n' + location.address + '\n\n'
line_bot_api.reply_message( # 回覆訊息
event.reply_token,
TextSendMessage(text=content)
)
return HttpResponse()
else:
return HttpResponseBadRequest()範例中,要特別注意的地方是,第5行需引用Location資料模型,這樣LINE Bot才有辦法存取PostgreSQL資料庫中的資料,也就是第33行,篩選Location資料模型對應的triplinebot_location資料表中,地區欄位(area)為使用者所發送的地區(event.message.text)資料,接著,透過Python迴圈,取得景點名稱及地址,組合成字串,回覆給使用者。
而LINE Bot其餘程式碼的詳細說明,可以參考[Python+LINE Bot教學]6步驟快速上手LINE Bot機器人文章。
五、LINE 設定Webhook URL
到目前為止,LINE Bot已經能夠連接PostgreSQL資料庫,並且可以依據使用者所發送的地區訊息,查詢資料庫中該地區的景點資料,最後,LINE Bot就需要一組對外的HTTPS網址(URL),讓使用者加入TripLineBot帳號好友後,能夠和LINE Bot進行連接。
在Django應用程式(triplinebot)下,新增urls.py檔案,來設定LINE Bot應用程式的網址,如下範例:
from django.urls import path
from . import views
urlpatterns = [
path('callback', views.callback)
]接著,開啟專案主程式的urls.py檔案,將LINE Bot應用程式的網址進行加入的動作,如下範例:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('triplinebot/', include('triplinebot.urls')),
]由於本地端的網址並不是HTTPS的網址,所以,這時候就可以使用[Python+LINE Bot教學]6步驟快速上手LINE Bot機器人文章中所介紹的ngrok工具,來幫忙產生一組隨機的HTTPS網址,如範例:
$ ngrok http 8000
執行結果

簡單來說,ngrok工具能夠利用本地端的IP埠號,隨機產生一組對外開放(Public)的HTTPS網址,這樣外部的所有使用者就可以存取本地端所執行的服務。
有了HTTPS網址後,前往LINE Developers,在TripLineBot的Messaging API頁籤下,有一個Webhook URL欄位,填寫LINE Bot的HTTPS網址,如下範例:
另外,要讓Django專案允許這個網域,所以需開啟settings.py檔案,在ALLOWED_HOSTS的地方進行加入,如下範例:
ALLOWED_HOSTS = [
'7075cc1c2962.ngrok.io'
]填寫完成後,就可以在LINE Developers上,掃描Messaging API頁籤下的QR code,加入好友後,就可以發送地區訊息給LINE Bot,讓它幫您尋找PostgreSQL資料庫中,該地區的景點資料了,如下圖:

六、小結
透過本文的範例教學,相信對於LINE Bot如何存取資料庫中的資料,進而回覆給使用者有價值的資訊,有基本的瞭解,大家趕快來依照本文的實作步驟,建立一個有趣的LINE Bot吧 :)
有想要看的教學內容嗎?歡迎利用以下的Google表單讓我知道,將有機會成為教學文章,分享給大家😊
- Python學習資源整理
- [Python+LINE Bot教學]6步驟快速上手LINE Bot機器人
- [Python+LINE Bot教學]建構具網頁爬蟲功能的LINE Bot機器人
- [Python+LINE Bot教學]提升使用者體驗的按鈕樣板訊息(Buttons template message)實用技巧
- [Python爬蟲教學]Python網頁爬蟲結合LINE Notify打造自動化訊息通知服務
- [Django教學1]3步驟快速安裝Django網站框架
- [Django教學2]建立Django應用程式(APP)
- [Django教學3]Django Migration(資料遷移)的重要觀念
- [Django教學15]Django連接PostgreSQL資料庫手把手教學




版主您好,我按照您的步驟下去實作一個一模一樣的練習機器人出現了一個問題,當我引用Location 資料模型時出現了 Class 'Location' has no 'objects' member,想請問版主我是哪邊步驟錯了嗎?還是另有問題?
回覆刪除您好: 可能的原因是文章第三節的部分實作有問題,也就是Django沒有成功的連結到PostgreSQL或沒有正確的執行Migration,可以檢查當您執行python migrate指令後,PostgreSQL資料庫是否有出現triplinebot_location資料表,如果沒有的話,建議重新建立Django專案,執行Migration,如果問題還是尚未解決,歡迎到Learn Code With Mike粉絲專頁私訊我,將協助您找出問題,謝謝 :)
刪除作者已經移除這則留言。
回覆刪除請問一下我照著步驟做到最後都可以
回覆刪除但是做完之後有些功能會沒辦法使用
for event in events:
if isinstance(event, MessageEvent):
# 篩選location資料表中,地區欄位為使用者發送地區的景點資料
locations = Location.objects.filter(area=event.message.text)
content = '' # 回覆使用者的內容
for location in locations:
content += location.name + '\n' + location.address + '\n\n'
line_bot_api.reply_message( # 回覆訊息
event.reply_token,
TextSendMessage(text=content)
)
if isinstance(event.message, TextMessage):
mtext = event.message.text
if mtext == '@按鈕樣板':
func.sendButton(event)
elif mtext == '@確認樣板':
func.sendConfirm(event)
return HttpResponse()
else:
return HttpResponseBadRequest()
請問在【一、建立LINE Bot】輸入以下的內容是在settings.py的那一個段落加入以下的文字,謝謝
回覆刪除【並且,新增剛剛所取得的兩個LINE Bot連結資訊,如下範例:
LINE_CHANNEL_ACCESS_TOKEN = 'Messaging API的Channel access token'
LINE_CHANNEL_SECRET = 'Basic settings的Channel Secret'】
如果使用mysql 程式碼也是一樣的嗎?
回覆刪除