
日常的資料分析工作中,有非常多的資料集需要處理,並且各資料集的結構與關係都不盡相同,這時候在利用Pandas套件來合併相關的資料集進行分析時,就可能發生不如預期的資料錯誤。
而Pandas套件常用的merge()及concat()合併資料方法(Method),也提供了資料驗證的機制,本文就來和大家分享其中的應用方式,避免在合併資料後,產生問題而影響分析結果。重點包含:
- Pandas merge()方法的合併資料驗證
- Pandas concat()方法的合併資料驗證
一、Pandas merge()方法的合併資料驗證
- udemy_course_data.csv
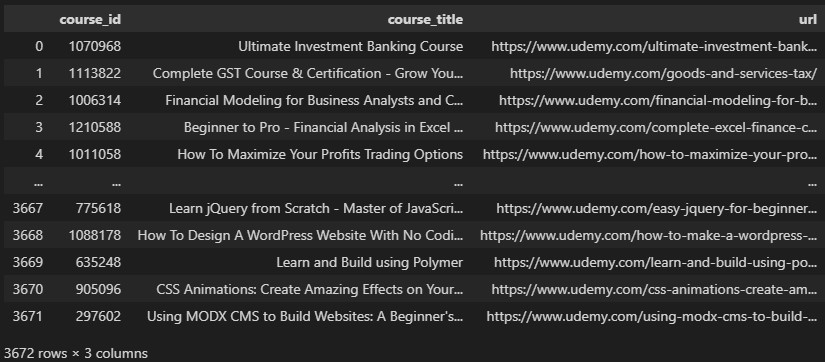
- udemy_course_detail_data.csv

假設,我們想要透過course_id欄位來進行兩個資料集一對一關係的「欄位資料合併」,如果udemy_course_detail_data.csv檔案的course_id欄位含有重複值,如下圖:
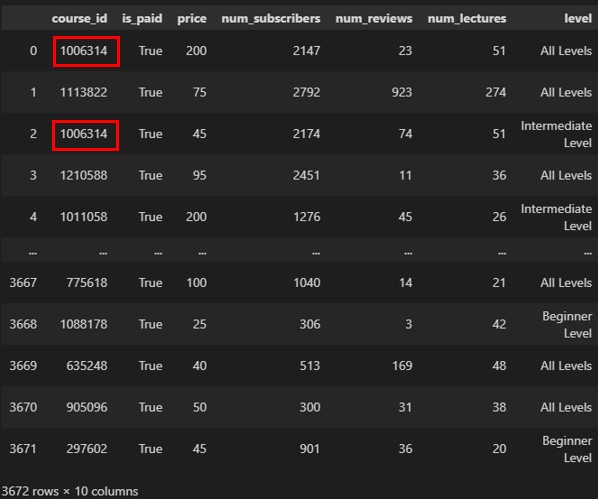
這時候,兩個資料集就會變成一對多的關係,如果在合併資料的過程中沒有進行驗證,就會發生跟預想的一對一資料合併不一樣,而導致分析結果錯誤。
Pandas套件的merge()方法(Method),對於「欄位資料合併」提供了validate關鍵字參數,來驗證以下四種資料集合併關係:
- one to one:一對一
- one to many:一對多
- many to one:多對一
- many to many:多對多
所以,想要利用Pandas套件的merge()方法(Method)來驗證一對一關係的資料合併,設定validate關鍵字參數即可,如下範例:
import pandas as pd
course_data = pd.read_csv('udemy_course_data.csv')
course_detail_data = pd.read_csv('udemy_course_detail_data.csv')
merge_df = course_data.merge(course_detail_data,
on='course_id',
validate='one_to_one')
print(merge_df)執行結果
MergeError: Merge keys are not unique in right dataset; not a one-to-one merge
其中,顯示了右邊資料集的主鍵欄位(course_id)有重複值,並非一對一的關係,讓我們得知合併資料的潛在問題,進而解決。
二、Pandas concat()方法的合併資料驗證
除此之外,在「資料內容合併」上,使用的Pandas套件concat()方法(Method),也提供了verify_integrity關鍵字參數,來驗證資料集的「資料內容合併」時,主鍵欄位資料是否重複。
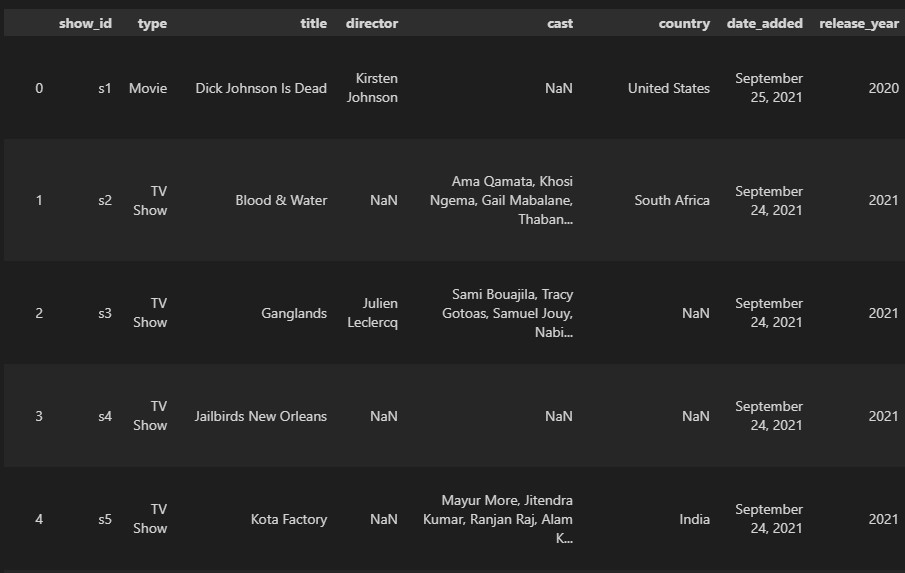
以Kaggle網站的Netflix Movies and TV Shows及Disney+ Movies and TV Shows資料集為例,可以分別看到它們的結構如下:
- netflix_titles.csv

- disney_plus_titles.csv

在使用Pandas套件的concat()方法(Method)進行資料內容合併時,預設verify_integrity關鍵字參數為False,所以兩個資料集的合併結果,如下範例:
import pandas as pd
netflix = pd.read_csv('netflix_titles.csv')
disney = pd.read_csv('disney_plus_titles.csv')
merge_df= pd.concat([netflix, disney])
print(merge_df)截取部分執行結果
import pandas as pd
netflix = pd.read_csv('netflix_titles.csv')
disney = pd.read_csv('disney_plus_titles.csv')
merge_df= pd.concat([netflix, disney])
duplicated = merge_df2.duplicated(subset=['show_id']).value_counts()
print(duplicated)執行結果
False 8807 True 1450 dtype: int64
所以,為了避免在合併資料後,主鍵欄位的資料重複,就可以將verify_integrity設定為True來進行驗證,如下範例:
import pandas as pd
netflix = pd.read_csv('netflix_titles.csv')
disney = pd.read_csv('disney_plus_titles.csv')
merge_df= pd.concat([netflix, disney]], verify_integrity=True)
print(merge_df)執行結果
ValueError: Indexes have overlapping values: Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
...
1440, 1441, 1442, 1443, 1444, 1445, 1446, 1447, 1448, 1449],
dtype='int64', length=1450)以上執行結果提醒了資料分析人員,合併資料會發生1450筆主鍵欄位資料重複的問題。
三、小結
在合併資料集時,利用Pandas套件的merge()及concat()方法(Method)關鍵字參數,就可以透過錯誤訊息快速得知合併後的潛在問題,進而找出解決方案,以確保合併後的資料正確性,Mike覺得非常實用,來和大家分享。
如果有其它技巧,歡迎在底下留言分享,或是本文有幫助到你,也歡迎在底下留言「有幫助」唷~
本文是筆者Mike在DataCamp平台上所學到的Pandas套件資料清理技巧,加以應用和大家分享。DataCamp平台上有非常多與資料科學、分析有關的教學,包含資料視覺化、清理、機器學習等,並且有專家帶領你完成資料分析專案,大家有興趣的話,可以加入DataCamp平台一起學習唷。
別忘了在下面訂閱本網站,以及幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
有想要看的教學內容嗎?歡迎利用以下的Google表單讓我知道,將有機會成為教學文章,分享給大家😊




留言
張貼留言