
在使用Python網頁爬蟲搜集資料的過程中,隨著時間的累積,資料量就會逐步的增加形成大數據,這時候,就會需要藉由雲端資源來協助我們進行資料分析。
而Google BigQuery雲端數據庫(Cloud Data Warehouse)就是一個非常強大的資料儲存分析工具,除了能夠儲存大量的數據外,還擁有很好的查詢效能,並且可以結合Google Data Studio來進行資料視覺化。
所以本文就接續[Python爬蟲教學]一學就會的Python網頁爬蟲動態讀取資料庫應用文章,來和大家分享,如何將Python網頁爬蟲爬取的資料,載入Pandas DataFrame後,存入Google BigQuery資料表,以利於分析。其中的實作步驟包含:
- 建立Google BigQuery資料表
- 建立Google BigQuery憑證
- Python網頁爬蟲寫入Google BigQuery
一、建立Google BigQuery資料表
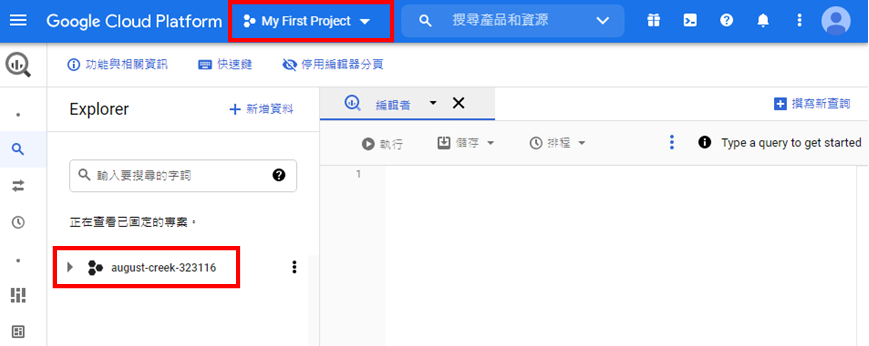
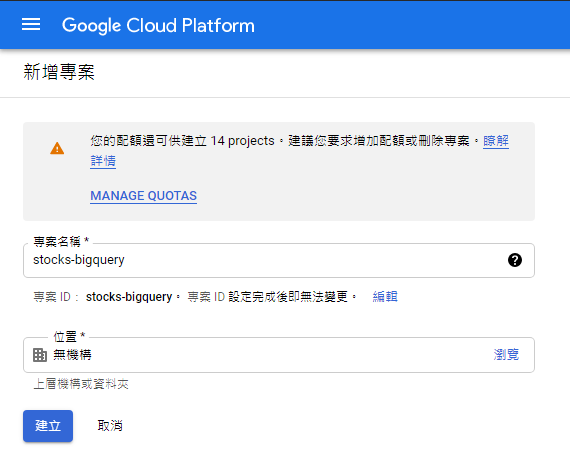
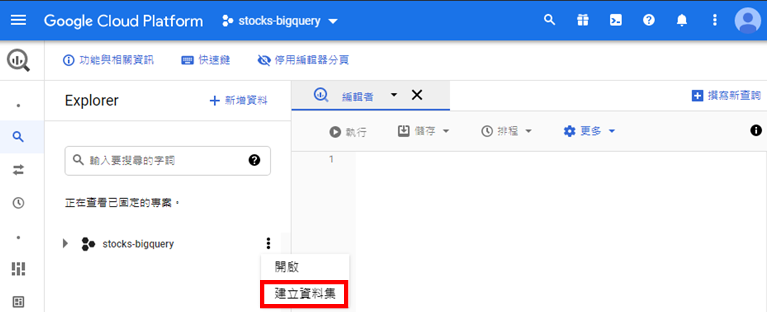
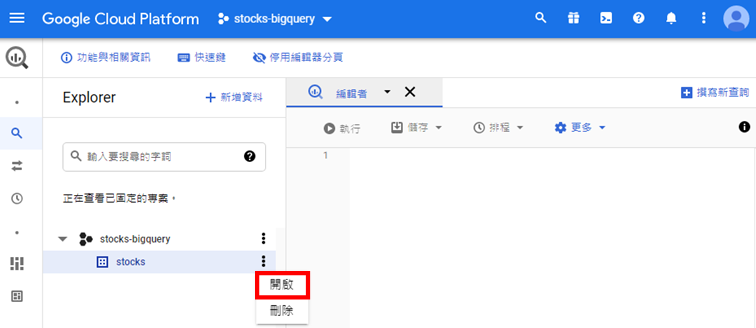
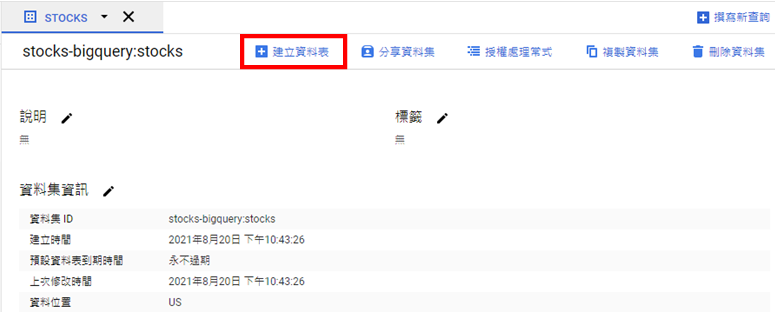
想要將Python網頁爬蟲爬取的資料存入Google BigQuery之前,就需要在上面建立所需的資料表。首先,前往Google BigQuery服務,如下圖:




二、建立Google BigQuery憑證
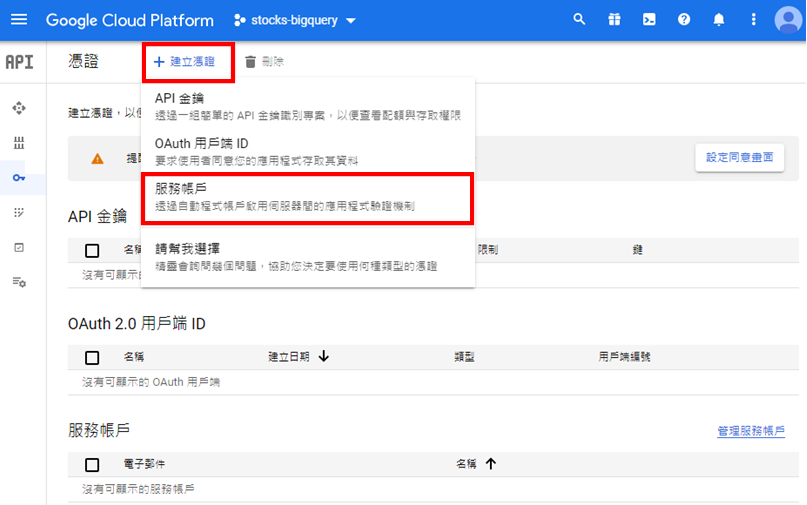
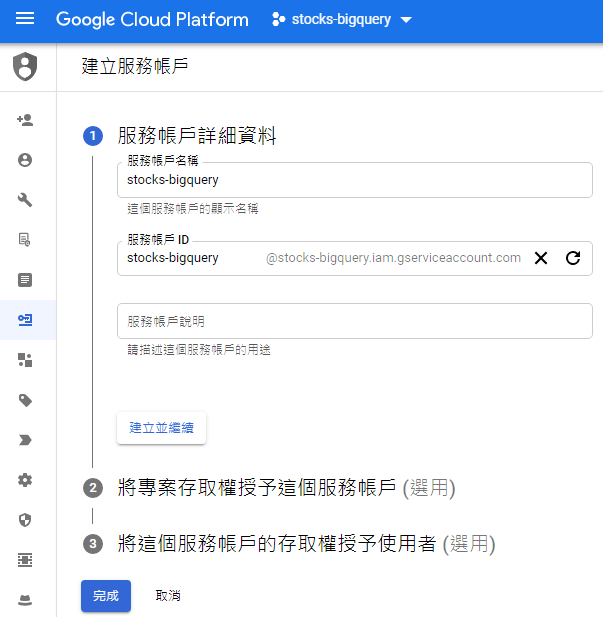
為了讓我們的專案能夠將資料寫入到Google BigQuery,就需要建立憑證(Credentials),位於選單的「API和服務」,如下圖:


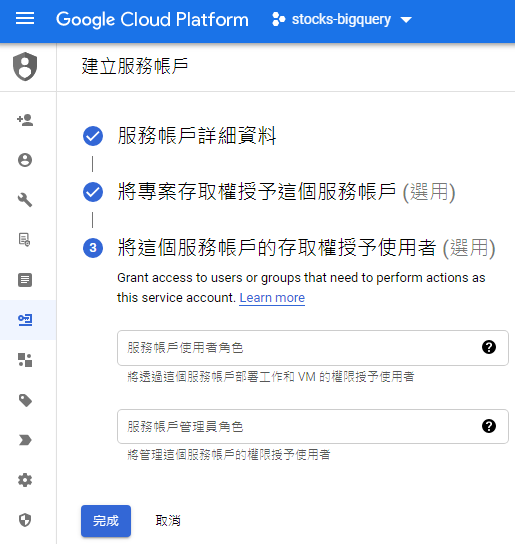



三、Python網頁爬蟲寫入Google BigQuery
Google BigQuery的資料表建置完成,來回顧一下[Python爬蟲教學]一學就會的Python網頁爬蟲動態讀取資料庫應用文章的股票爬取結果,如下範例:
from datetime import datetime
import requests
import sqlite3
today = datetime.now().strftime('%Y%m%d') #西元年(yyyymmdd)
chinese_today = f"{(datetime.now().year - 1911)}/{datetime.now().strftime('%m/%d')}" #民國年(yyy/mm/dd)
conn = sqlite3.connect('Stocks.db')
cursor = conn.cursor()
cursor.execute('SELECT StockNo FROM StockNumbers')
combined = [] #合併結果
for stock_no in cursor.fetchall():
response = requests.get(
f'https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=json&date={today}&stockNo={stock_no[0]}')
response_data = response.json()['data']
result = [data for index, data in enumerate(response_data) if chinese_today in response_data[index]]
if result: #如果有資料
result[0].insert(0, stock_no[0])
combined.append(result[0])
print(combined)[['2330', '110/08/20', '47,741,449', '26,565,551,162', '560.00', '563.00', '551.00', '552.00', '-7.00', '72,684'], ['2409', '110/08/20', '187,871,279', '3,616,408,609', '19.75', '19.85', '19.00', '19.05', '-0.70', '45,042'], ['2382','110/08/20', '6,821,731', '516,383,698', '75.90', '76.50', '74.80', '75.60', '+0.70', '4,082']]
而要將以上的爬取結果存入Google BigQuery,就需要先將資料載入Pandas DataFrame,再進行存入的動作,所以,利用以下指令來安裝相關套件,如下:
pip install pandas pip install --upgrade google-cloud-bigquery pip install pyarrow
其中pyarrow為Google BigQuery載入Pandas DataFrame資料的相依性套件,特別注意需要Python 64位元才可成功安裝。
接著,引用pandas、bigquery及os模組(Module),如下範例:
from datetime import datetime
import requests
import sqlite3
from google.cloud import bigquery
import pandas as pd
import os
today = datetime.now().strftime('%Y%m%d') #西元年(yyyymmdd)
chinese_today = f"{(datetime.now().year - 1911)}/{datetime.now().strftime('%m/%d')}" #民國年(yyy/mm/dd)
conn = sqlite3.connect('Stocks.db')
cursor = conn.cursor()
cursor.execute('SELECT StockNo FROM StockNumbers')
combined = [] #合併結果
for stock_no in cursor.fetchall():
response = requests.get(
f'https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=json&date={today}&stockNo={stock_no[0]}')
response_data = response.json()['data']
result = [data for index, data in enumerate(response_data) if chinese_today in response_data[index]]
if result: #如果有資料
result[0].insert(0, stock_no[0])
combined.append(result[0])
print(combined)將爬取的股票結果存入Pandas DataFrame中,如下範例第28、29行:
from datetime import datetime
import requests
import sqlite3
from google.cloud import bigquery
import pandas as pd
import os
today = datetime.now().strftime('%Y%m%d') #西元年(yyyymmdd)
chinese_today = f"{(datetime.now().year - 1911)}/{datetime.now().strftime('%m/%d')}" #民國年(yyy/mm/dd)
conn = sqlite3.connect('Stocks.db')
cursor = conn.cursor()
cursor.execute('SELECT StockNo FROM StockNumbers')
combined = [] #合併結果
for stock_no in cursor.fetchall():
response = requests.get(
f'https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=json&date={today}&stockNo={stock_no[0]}')
response_data = response.json()['data']
result = [data for index, data in enumerate(response_data) if chinese_today in response_data[index]]
if result: #如果有資料
result[0].insert(0, stock_no[0])
combined.append(result[0])
df = pd.DataFrame(combined, columns=['stock_no', 'traded_date', 'traded_shares', 'traded_price',
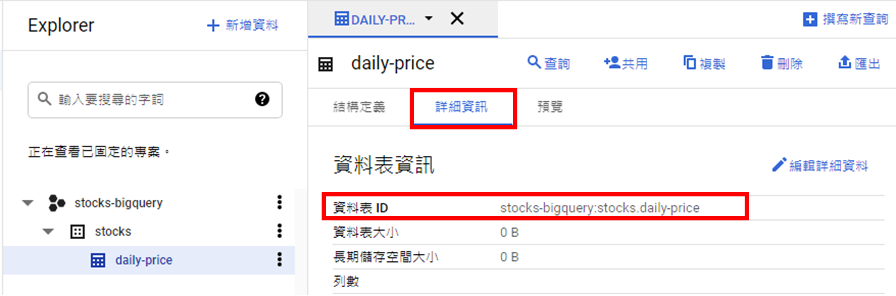
'opening_price', 'high_price', 'low_price', 'closing_price', 'gross_spread', 'trading_volume'])PS:columns(欄位名稱)需和Google BigQuery資料表(daily-price)所定義的欄位名稱相同。
接下來,設定Google的憑證路徑,並且利用os模組(Module)來設定「GOOGLE_APPLICATION_CREDENTIALS」環境變數,如下範例第31、32行:
from datetime import datetime
import requests
import sqlite3
from google.cloud import bigquery
import pandas as pd
import os
today = datetime.now().strftime('%Y%m%d') #西元年(yyyymmdd)
chinese_today = f"{(datetime.now().year - 1911)}/{datetime.now().strftime('%m/%d')}" #民國年(yyy/mm/dd)
conn = sqlite3.connect('Stocks.db')
cursor = conn.cursor()
cursor.execute('SELECT StockNo FROM StockNumbers')
combined = [] #合併結果
for stock_no in cursor.fetchall():
response = requests.get(
f'https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=json&date={today}&stockNo={stock_no[0]}')
response_data = response.json()['data']
result = [data for index, data in enumerate(response_data) if chinese_today in response_data[index]]
if result: #如果有資料
result[0].insert(0, stock_no[0])
combined.append(result[0])
df = pd.DataFrame(combined, columns=['stock_no', 'traded_date', 'traded_shares', 'traded_price',
'opening_price', 'high_price', 'low_price', 'closing_price', 'gross_spread', 'trading_volume'])
credentials_path = 'C:\\Desktop\\stock\\stocks-bigquery-key.json'
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credentials_path這時後,就可以建立Google BigQuery用戶端物件,透過load_table_from_dataframe方法(Method),設定資料表ID,載入Pandas DataFrame中的爬取資料,如下範例第34~38行:
from datetime import datetime
import requests
import sqlite3
from google.cloud import bigquery
import pandas as pd
import os
today = datetime.now().strftime('%Y%m%d') #西元年(yyyymmdd)
chinese_today = f"{(datetime.now().year - 1911)}/{datetime.now().strftime('%m/%d')}" #民國年(yyy/mm/dd)
conn = sqlite3.connect('Stocks.db')
cursor = conn.cursor()
cursor.execute('SELECT StockNo FROM StockNumbers')
combined = [] #合併結果
for stock_no in cursor.fetchall():
response = requests.get(
f'https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=json&date={today}&stockNo={stock_no[0]}')
response_data = response.json()['data']
result = [data for index, data in enumerate(response_data) if chinese_today in response_data[index]]
if result: #如果有資料
result[0].insert(0, stock_no[0])
combined.append(result[0])
df = pd.DataFrame(combined, columns=['stock_no', 'traded_date', 'traded_shares', 'traded_price',
'opening_price', 'high_price', 'low_price', 'closing_price', 'gross_spread', 'trading_volume'])
credentials_path = 'C:\\Desktop\\stock\\stocks-bigquery-key.json'
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credentials_path
client = bigquery.Client()
table_id = 'stocks-bigquery.stocks.daily-price'
job = client.load_table_from_dataframe(df, table_id)
job.result() #等待寫入完成PS.特別注意Google BigQuery的資料表ID需將「:」修改為「.」。
如果想要在執行後,瞭解寫入多少筆資料到Google BigQuery資料表(daily-price),則可以利用get_table()方法(Method),傳入資料表ID,取得相關的訊息,如下範例第40、41行:
from datetime import datetime
import requests
import sqlite3
from google.cloud import bigquery
import pandas as pd
import os
today = datetime.now().strftime('%Y%m%d') #西元年(yyyymmdd)
chinese_today = f"{(datetime.now().year - 1911)}/{datetime.now().strftime('%m/%d')}" #民國年(yyy/mm/dd)
conn = sqlite3.connect('Stocks.db')
cursor = conn.cursor()
cursor.execute('SELECT StockNo FROM StockNumbers')
combined = [] #合併結果
for stock_no in cursor.fetchall():
response = requests.get(
f'https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=json&date={today}&stockNo={stock_no[0]}')
response_data = response.json()['data']
result = [data for index, data in enumerate(response_data) if chinese_today in response_data[index]]
if result: #如果有資料
result[0].insert(0, stock_no[0])
combined.append(result[0])
df = pd.DataFrame(combined, columns=['stock_no', 'traded_date', 'traded_shares', 'traded_price',
'opening_price', 'high_price', 'low_price', 'closing_price', 'gross_spread', 'trading_volume'])
credentials_path = 'C:\\Desktop\\stock\\stocks-bigquery-key.json'
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credentials_path
client = bigquery.Client()
table_id = 'stocks-bigquery.stocks.daily-price'
job = client.load_table_from_dataframe(df, table_id)
job.result() #等待寫入完成
table = client.get_table(table_id)
print(f'已存入{table.num_rows}筆資料到{table_id}')執行結果
已存入3筆資料到stocks-bigquery.stocks.daily-price
開啟Google BigQuery資料表(daily-price),重新整理網頁後,在「預覽」頁籤就可以看到寫入的資料,如下圖:

四、小結
本文手把手帶大家將Python網頁爬蟲爬取的資料載入Pandas DataFrame後,寫入Google BigQuery雲端數據庫(Cloud Data Warehouse),也就是先建立Google BigQuery資料表及憑證後,就能夠透過Google BigQuery用戶端模組(Module),將爬取的資料進行寫入,後續就可以藉由Google BigQuery的快速查詢效能,來提升資料分析效率。
大家是否也有使用過Google BigQuery服務呢?都是應用在什麼情境下?歡迎在底下留言和我分享交流唷~
如果您喜歡我的文章,別忘了在下面訂閱本網站,以及幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。




留言
張貼留言