
本文內容於2021/11/21更新
在數據爆炸的時代,想要透過資料分析來取得其中有價值的資訊,就需要先獲取大量的資料,並且有效的儲存起來,如此才能夠進行多樣化的應用。而網頁則是最常見的資料蒐集管道,通常會利用API、Open Data(開放資料)或Python網頁爬蟲等技術來進行取得,那又該如何把這些資料儲存起來呢?
本文將以Yahoo奇摩股市為例,分享如何利用Python網頁爬蟲取得關注的股票資料後,存入MySQL資料庫中,讓後續能夠進行資料分析使用。其中的重點包含:
- Yahoo奇摩股市網頁分析
- 建置Python網頁爬蟲
- 建立MySQL資料庫
- 建立MySQL資料表
- 存入爬取的網頁資料
一、Yahoo奇摩股市網頁分析
在進行Python網頁爬蟲開發前,首先來分析一下所要爬取的Yahoo股市網頁結構。前往Yahoo奇摩官方網站,在左側的地方可以看到「股市」的選項,如下圖:



瞭解想要爬取的目標資料後,在一般情況下,用戶通常會關注一支以上的股票,如果要透過Python網頁爬蟲來自動化取得資料的話,該如何切換到另一支股票呢?
這時候可以看到上方的網址,最後都會帶有股票代號的參數,如下圖:

二、建置Python網頁爬蟲
Yahoo奇摩股市網頁分析好後,接下來就可以進行Python網頁爬蟲的開發,其中本文使用物件導向的設計,詳細的觀念可以參考[Python物件導向]淺談Python類別(Class)文章。
首先,利用以下的指令來安裝Python網頁爬蟲開發時所需的套件:
$ pip install beautifulsoup4
$ pip install requests
$ pip install lxml
其中lxml為BeautifulSoup所支援的HTML解析器,執行速度較快且擁有較佳的容錯能力。
開啟開發工具,本文以Visual Studio Code為例,建立scraper.py檔案,引用beautifulsoup及requests模組(Module),如下範例:
from bs4 import BeautifulSoup
import requests接著,建立一個股票類別(Stock),其中包含建構式(Constructor)及爬取(Scrape)方法(Method),如下範例:
from bs4 import BeautifulSoup
import requests
class Stock:
#建構式
def __init__(self):
pass
#爬取
def scrape(self):
pass由於在初始化股票(Stock)物件時,想要讓用戶能夠傳入多個股票代碼,以便可以利用Python網頁爬蟲取得不同股票的當日行情資料,所以,在建構式(Constructor)的地方使用*args參數,將傳入的多個股票代碼打包成一個元組(Tuple),詳細的用法觀念可以參考[Python教學]5個必知的Python Function觀念整理,如下範例:
from bs4 import BeautifulSoup
import requests
class Stock:
#建構式
def __init__(self, *stock_numbers):
self.stock_numbers = stock_numbers
print(self.stock_numbers)
#爬取
def scrape(self):
pass
stock = Stock("2451","2454") #建立Stock物件執行結果
('2451', '2454')範例中,在股票(Stock)物件初始化時,傳入兩個股票代碼,使用*args參數後,就會打包成元組(Tuple),這樣在等一下開發Python網頁爬蟲時,就能夠透過迴圈的方式,讀取元組(Tuple)中的股票代碼,取得對應的當日行情資料。
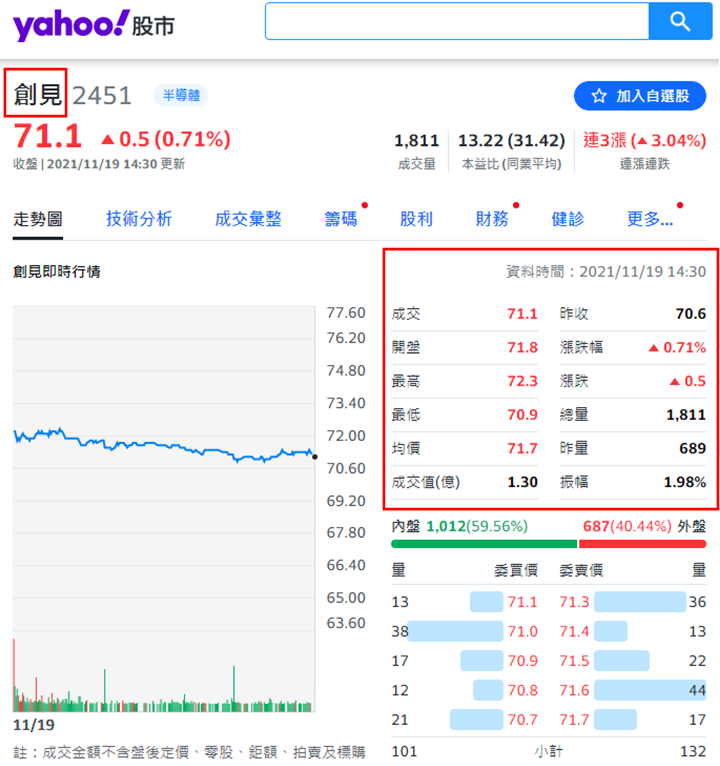
接下來,在scrape()方法(Method)中,利用requests套件發送GET請求到Yahoo奇摩股市的「2451創建」當日行情網頁,取得回傳結果(原始碼)後,使用lxml解析器來建立BeautifulSoup物件,如下範例:
from bs4 import BeautifulSoup
import requests
class Stock:
#建構式
def __init__(self, *stock_numbers):
self.stock_numbers = stock_numbers
#爬取
def scrape(self):
response = requests.get("https://tw.stock.yahoo.com/quote/2451")
soup = BeautifulSoup(response.text, "lxml")有了網頁原始碼的回傳結果,就可以先來爬取「公司名稱」及「資料時間」,在網頁上點擊右鍵,選擇「檢查」,即可看到HTML原始碼,如下圖:
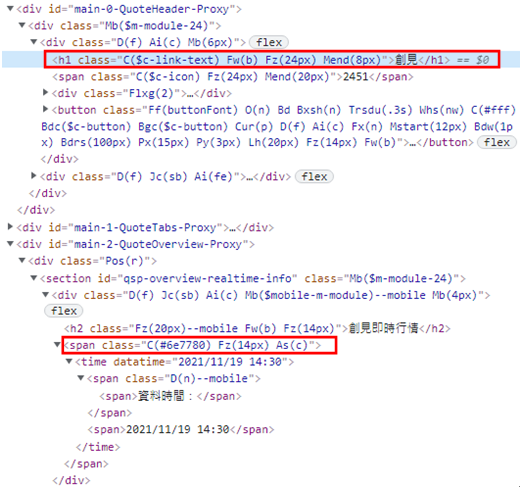
從上圖可以看到,分別利用「公司名稱」的<h1>標籤、「資料時間」的<span>標籤,以及各自的樣式類別(class),即可進行元素的定位,再透過BeautifulSoup套件的getText()方法就可以取得其中的資料,如下範例:
from bs4 import BeautifulSoup
import requests
class Stock:
#建構式
def __init__(self, *stock_numbers):
self.stock_numbers = stock_numbers
#爬取
def scrape(self):
response = requests.get("https://tw.stock.yahoo.com/quote/2451")
soup = BeautifulSoup(response.text, 'lxml')
stock_name = soup.find('h1', {'class': 'C($c-link-text) Fw(b) Fz(24px) Mend(8px)'}).getText()
stock_date = soup.find('span', {'class': 'C(#6e7780) Fz(14px) As(c)'}).getText()其中,由於「資料時間」文字是多餘的,這時候就可以使用Python的replace()方法(Method),將這個文字去掉,再利用字串的裁切語法,分別取得「日期」及「時間」資料,如下範例:
from bs4 import BeautifulSoup
import requests
class Stock:
#建構式
def __init__(self, *stock_numbers):
self.stock_numbers = stock_numbers
#爬取
def scrape(self):
response = requests.get("https://tw.stock.yahoo.com/quote/2451")
soup = BeautifulSoup(response.text, 'lxml')
stock_name = soup.find('h1', {'class': 'C($c-link-text) Fw(b) Fz(24px) Mend(8px)'}).getText()
stock_date = soup.find('span', {'class': 'C(#6e7780) Fz(14px) As(c)'}).getText().replace('資料時間:', '')
market_date = stock_date[0:10] #日期
market_time = stock_date[11:16] #時間而「當日行情資料」比照同樣的方式,可以看到如下圖的HTML原始碼:

首先,利用<ul>標籤及它的樣式類別(class),透過BeautifulSoup套件的find()方法,取得「當日行情資料」清單,如下範例:
from bs4 import BeautifulSoup
import requests
class Stock:
#建構式
def __init__(self, *stock_numbers):
self.stock_numbers = stock_numbers
#爬取
def scrape(self):
response = requests.get("https://tw.stock.yahoo.com/quote/2451")
soup = BeautifulSoup(response.text, 'lxml')
stock_name = soup.find('h1', {'class': 'C($c-link-text) Fw(b) Fz(24px) Mend(8px)'}).getText()
stock_date = soup.find('span', {'class': 'C(#6e7780) Fz(14px) As(c)'}).getText().replace('資料時間:', '')
market_date = stock_date[0:10] #日期
market_time = stock_date[11:16] #時間
ul = soup.find('ul', {'class': 'D(f) Fld(c) Flw(w) H(192px) Mx(-10px)'})定位到「當日行情資料」清單後,就可以再利用find_all()方法(Method)取得底下的所有項目(li),如下範例:
from bs4 import BeautifulSoup
import requests
class Stock:
#建構式
def __init__(self, *stock_numbers):
self.stock_numbers = stock_numbers
#爬取
def scrape(self):
response = requests.get("https://tw.stock.yahoo.com/quote/2451")
soup = BeautifulSoup(response.text, 'lxml')
stock_name = soup.find('h1', {'class': 'C($c-link-text) Fw(b) Fz(24px) Mend(8px)'}).getText()
stock_date = soup.find('span', {'class': 'C(#6e7780) Fz(14px) As(c)'}).getText().replace('資料時間:', '')
market_date = stock_date[0:10] #日期
market_time = stock_date[11:16] #時間
ul = soup.find('ul', {'class': 'D(f) Fld(c) Flw(w) H(192px) Mx(-10px)'})
items = ul.find_all('li', {
'class': 'price-detail-item H(32px) Mx(10px) D(f) Jc(sb) Ai(c) Bxz(bb) Px(0px) Py(4px) Bdbs(s) Bdbc($bd-primary-divider) Bdbw(1px)'})接著,就可以利用Python的Comprehension語法,讀取每一個項目(li)下的第2個<span>標籤資料值,並且存放在元組(Tuple)中,如下範例:
from bs4 import BeautifulSoup
import requests
class Stock:
#建構式
def __init__(self, *stock_numbers):
self.stock_numbers = stock_numbers
#爬取
def scrape(self):
response = requests.get("https://tw.stock.yahoo.com/quote/2451")
soup = BeautifulSoup(response.text, 'lxml')
stock_name = soup.find('h1', {'class': 'C($c-link-text) Fw(b) Fz(24px) Mend(8px)'}).getText()
stock_date = soup.find('span', {'class': 'C(#6e7780) Fz(14px) As(c)'}).getText().replace('資料時間:', '')
market_date = stock_date[0:10] #日期
market_time = stock_date[11:16] #時間
ul = soup.find('ul', {'class': 'D(f) Fld(c) Flw(w) H(192px) Mx(-10px)'})
items = ul.find_all('li', {
'class': 'price-detail-item H(32px) Mx(10px) D(f) Jc(sb) Ai(c) Bxz(bb) Px(0px) Py(4px) Bdbs(s) Bdbc($bd-primary-divider) Bdbw(1px)'})
data = tuple(item.find_all('span')[1].getText() for item in items)這時候,就可以依需求,將剛剛所爬到的「日期」、「公司名稱」、「時間」及「當日行情資料」打包成一個元組(Tuple),讓後續能夠順利寫入資料庫中,如下範例:
from bs4 import BeautifulSoup
import requests
class Stock:
#建構式
def __init__(self, *stock_numbers):
self.stock_numbers = stock_numbers
#爬取
def scrape(self):
response = requests.get("https://tw.stock.yahoo.com/quote/2451")
soup = BeautifulSoup(response.text, 'lxml')
stock_name = soup.find('h1', {'class': 'C($c-link-text) Fw(b) Fz(24px) Mend(8px)'}).getText()
stock_date = soup.find('span', {'class': 'C(#6e7780) Fz(14px) As(c)'}).getText().replace('資料時間:', '')
market_date = stock_date[0:10] #日期
market_time = stock_date[11:16] #時間
ul = soup.find('ul', {'class': 'D(f) Fld(c) Flw(w) H(192px) Mx(-10px)'})
items = ul.find_all('li', {
'class': 'price-detail-item H(32px) Mx(10px) D(f) Jc(sb) Ai(c) Bxz(bb) Px(0px) Py(4px) Bdbs(s) Bdbc($bd-primary-divider) Bdbw(1px)'})
data = tuple(item.find_all('span')[1].getText() for item in items)
(market_date, stock_name, market_time) + data到目前為止,都只是爬取一支股票的資料,當有多支股票時,就需要透過迴圈來重覆執行,並且使用串列(List),將每一支股票的爬取結果元組(Tuple)打包起來,如下範例:
from bs4 import BeautifulSoup
import requests
class Stock:
#建構式
def __init__(self, *stock_numbers):
self.stock_numbers = stock_numbers
#爬取
def scrape(self):
result = list() # 最終結果
for stock_number in self.stock_numbers:
response = requests.get(f"https://tw.stock.yahoo.com/quote/{stock_number}")
soup = BeautifulSoup(response.text, 'lxml')
stock_name = soup.find('h1', {'class': 'C($c-link-text) Fw(b) Fz(24px) Mend(8px)'}).getText()
stock_date = soup.find('span', {'class': 'C(#6e7780) Fz(14px) As(c)'}).getText().replace('資料時間:', '')
market_date = stock_date[0:10] #日期
market_time = stock_date[11:16] #時間
ul = soup.find('ul', {'class': 'D(f) Fld(c) Flw(w) H(192px) Mx(-10px)'})
items = ul.find_all('li', {
'class': 'price-detail-item H(32px) Mx(10px) D(f) Jc(sb) Ai(c) Bxz(bb) Px(0px) Py(4px) Bdbs(s) Bdbc($bd-primary-divider) Bdbw(1px)'})
data = tuple(item.find_all('span')[1].getText() for item in items)
result.append((market_date, stock_name, market_time) + data)
return result
stock = Stock('2451', '2454') #建立Stock物件
print(stock.scrape()) #印出爬取結果執行結果
[
('2021/11/19', '創見', '14:30', '71.1', '71.8', '72.3', '70.9', '71.7', '1.30', '70.6', '0.71%', '0.5', '1,811', '689', '1.98%'),
('2021/11/19', '聯發科', '14:30', '1,090', '1,115', '1,120', '1,060', '1,089', '108.37', '1,085', '0.46%', '5', '9,952', '12,474', '5.53%')
]特別注意範例中的第17行,網址的最後需搭配迴圈替換初始化的股票代碼。
三、建立MySQL資料庫
Python網頁爬蟲開發完成後,接下來,就要準備MySQL資料庫,來儲存爬取的股票「當日行情資料」。
MySQL資料庫的安裝方式可以參考[Python實戰應用]掌握Python連結MySQL資料庫的重要操作文章的第二節。
安裝完成後,開啟MySQL Workbench資料庫管理工具,可以在Windows作業系統上,利用「開始」的搜尋功能,輸入關鍵字來進行開啟,如下圖:


填入資料庫名稱及設定utf8字元集,點擊右下角的「Apply」即可,如下圖:

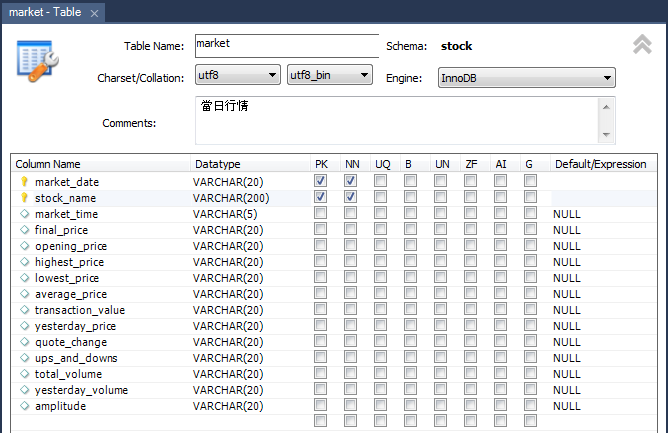
四、建立MySQL資料表
在建立的資料庫(stock)下,點擊「Table(資料表)」右鍵,選擇「Create Table」,如下圖:

五、存入爬取的網頁資料
MySQL資料庫準備好後,現在就可以儲存Python網頁爬蟲所取得的資料,而要讓Python應用程式能夠與MySQL資料庫連接,需要安裝pymysql套件,可以利用以下的指令來安裝:
$ pip install pymysql開啟scraper.py檔案,引用pymysql套件,並且新增一個save()方法(Method),含有股票資料的參數(stocks),如下範例:
import pymysql def save(self, stocks):
接著,在save()方法(Method)裡面設定MySQL資料庫的連線資訊,如下範例:
import pymysql
def save(self, stocks):
db_settings = {
"host": "127.0.0.1",
"port": 3306,
"user": "root",
"password": "******",
"db": "stock",
"charset": "utf8"
}有了連線的資訊,就可以透過pymysql套件的connect()方法(Method)來進行連接,如下範例:
import pymysql
def save(self, stocks):
db_settings = {
"host": "127.0.0.1",
"port": 3306,
"user": "root",
"password": "******",
"db": "stock",
"charset": "utf8"
}
try:
conn = pymysql.connect(**db_settings)
except Exception as ex:
print("Exception:", ex)而要進行資料庫的操作,就需要有cursor物件,才能夠執行MySQL的新增資料指令,如下範例:
import pymysql def save(self, stocks): db_settings = { "host": "127.0.0.1", "port": 3306, "user": "root", "password": "******", "db": "stock", "charset": "utf8" } try: conn = pymysql.connect(**db_settings) with conn.cursor() as cursor: sql = """INSERT INTO market( market_date, stock_name, market_time, final_price, opening_price, highest_price, lowest_price, average_price, transaction_value, yesterday_price, quote_change, ups_and_downs, total_volume, yesterday_volume, amplitude) VALUES(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)""" for stock in stocks: cursor.execute(sql, stock) conn.commit() except Exception as ex: print("Exception:", ex)
範例中,第18行使用with陳述式,在資料庫操作完成後,會自動釋放連線的資源。另外,第37行透過Python迴圈,讀取傳入的股票資料串列(stocks),將每一支股票資料傳入MySQL的新增資料指令(sql)中,最後,利用commit()方法(Method)進行儲存。
完成資料庫的存入方法(save)後,現在,建立一個股票(Stock)物件,傳入兩個公司的股票代碼來進行初始化,接著,呼叫scrape()方法(Method)爬取Yahoo奇摩股市的「當日行情資料」,將回傳的串列(List)結果傳入save()方法(Method),來存入MySQL資料庫中,如下範例:
stock = Stock('2451', '2454') #建立Stock物件
stock.save(stock.scrape()) #將爬取的結果存入MySQL資料庫中截取部分執行結果

六、小結
透過本文的實際範例教學,瞭解如何將Python網頁爬蟲所取得的資料有效存入MySQL資料庫中,後續即可利用這些資料來進行分析、圖形化或提供預測的服務等,詳細的程式碼可以參考以下的GitHub網址。另外,您有關注的股票嗎?利用本文的教學來開發一個Python網頁爬蟲,自動化取得股票資料吧。
有想要看的教學內容嗎?歡迎利用以下的Google表單讓我知道,將有機會成為教學文章,分享給大家😊
Python學習資源
Python網頁爬蟲推薦課程
Python網頁爬蟲-BeautifulSoup教學
Python網頁爬蟲-Selenium教學
Python非同步網頁爬蟲
Python網頁爬蟲應用
Python網頁爬蟲部署
Python網頁爬蟲資料儲存
Python網頁爬蟲技巧
參考資料
本書的教學方式非常的基礎和直覺,沒有過多的變化應用,所以適合想要入門學習Python網頁爬蟲的讀者,並且約有20個網站的爬取範例,可以拿來參考。其中,除了包含常見的BeautifulSoup、Selenium及Scrapy教學外,也有各種檔案類型及Pandas模組的使用方式。
本文即是參考書中的Yahoo奇摩股市範例,加以改寫成實務上的小專案,整合MySQL資料庫,儲存Python網頁爬蟲所取得的資料。




謝謝版主分享的教學文,很棒的。
回覆刪除感謝您的支持阿 :)
刪除感謝版主分享教學,
回覆刪除請問"特別注意範例中的第18行,網址的最後參數需搭配迴圈替換初始化的股票代碼。"
我可以在哪邊學習?
謝謝
CHUN您好:
刪除其實第18行的部分就是兩個字串的連接,可以參考以下兩篇文章:
1. https://www.learncodewithmike.com/2019/11/python4-python.html
2. https://www.learncodewithmike.com/2019/12/python.html
希望有幫助到您 :)
謝謝老師的分享
回覆刪除請問:如果我有股票代碼清單(txt or xlsx)要怎麼讓這些代碼填入stock = Stock('代碼1','代碼2')
謝謝!
Ear您好:
刪除讀取Excel檔案中的資料可以參考以下的文章:
https://www.learncodewithmike.com/2020/12/read-excel-file-using-pandas.html
希望對您有所幫助,感謝您的提問唷 :)
你好請問一下
回覆刪除執行結果
('2451', '2454')
這邊是怎麼執行的?
因為我是用Django, 我是寫在自己建立的app裡面,views.py的裡面
您好,如果在Django專案中,可以將本文的Stock類別寫在獨立的檔案(ex:scraper.py),接著,在views.py檔案中進行引用,就可以呼叫以下兩行:
刪除stock = Stock('2451', '2454') #建立Stock物件
stock.save(stock.scrape()) #將爬取的結果存入MySQL資料庫中
可以參考我的https://www.learncodewithmike.com/2020/10/django-web-scraping.html文章,結合Django網站與Python網頁爬蟲的實作,希望對您有幫助,感謝您的提問 :)
你好,請問如何把爬取到的資料,用應用程式做出互動式介面顯示出來(如同隨身營業員的圖表介面)
回覆刪除您好,這個可能就會牽扯到手機APP的開發,大致上的開發邏輯有以下兩種:
刪除1.在開發手機APP時,將APP讀取的資料庫,連接至爬蟲所存入的資料庫,即可在APP上顯示網頁爬蟲所爬取的資料,不過,這個方法就會有時間差,因為APP是讀取資料庫中的資料。
2.直接在手機APP中,整合網頁爬蟲,即時顯示所爬取的資料。
建議您可能需要survey一下手機APP的開發教學,然後再將網頁爬蟲整合進去,即可達成 :)
Exception: (1054, "Unknown column 'highest_price' in 'field list'"←出現錯誤
回覆刪除在網路上找了許多方法,改了幾次還是無法成功...想請問應該如何改正
您好,確認一下SQL指令的INSERT語法中,highest_price是否有拼錯,以及MySQL的market資料表是否有定義highest_price欄位?
刪除您好,請問股票的數字該怎麼變成讀取自己輸入的值呢?
回覆刪除例如:輸入2303
執行stock=Stock('2303')
您好,可以使用Python內建的input()方法(Method),來取得在Terminal視窗中所輸入的值,如下範例:
刪除stock_number = input("請輸入股票代碼: ")
stock = Stock(stock_number)
更詳細的用法教學可以參考以下文章第四節的第7個input()方法(Method):
https://www.learncodewithmike.com/2019/11/python4-python.html
作者已經移除這則留言。
回覆刪除作者已經移除這則留言。
刪除不好意思我依照您的教學 在執行code時出現 Exception: Cursor closed
回覆刪除MySQL資料庫也沒有更新
請問要如何在vscode用python連接mysql呢?
回覆刪除發生例外狀況: AttributeError
回覆刪除'NoneType' object has no attribute 'find_all'
File "D:\Python\scraper.py", line 34, in scrape
items = ul.find_all('li', {
File "D:\Python\scraper.py", line 44, in
print(stock.scrape()) # 印出爬取結果
出了問題無法出現爬取出的結果
老師,您好,我試著按照您的語法寫在PyCharm裡頭,不過現在卡在您語法中的第20行,每次執行時都會出現 AttributeError: 'NoneType' object has no attribute 'getText',我找遍資料但仍然不知道該如何解決這個問題...希望您可以解惑,謝謝!
回覆刪除問完問題後又好好看了一遍,我終於發現我的錯誤了!謝謝~!
刪除