
本文就以Accupass網站的精選活動為例,來分享Scrapy框架整合Selenium套件,開發Python網頁爬蟲的流程,包含:
- 建立Scrapy網頁爬蟲
- 安裝scrapy-selenium套件
- Scrapy整合Selenium爬取動態網頁
一、建立Scrapy網頁爬蟲
在開始本文的實作前,如果對於Scrapy框架的結構還不熟悉的話,可以先參考[Scrapy教學1]快速入門Scrapy框架的5個執行模組及架構文章。
首先,利用以下指令安裝Scrapy框架:
$ pip install scrapy
接著,新增一個資料夾,並且使用命令提示字元切換到該資料夾的目錄下,建立Scrapy專案,如下:
$ scrapy startproject accupass_scraper .
PS.特別注意指令最後要加「.」,代表在目前路徑下建立專案。
有了專案後,就能夠利用以下指令建立Scrapy網頁爬蟲:
$ scrapy genspider accupass accupass.com
到目前為止,Scrapy專案的結構如下圖:
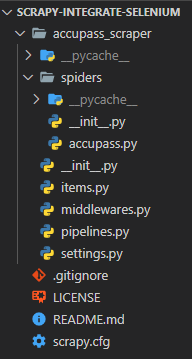
二、安裝scrapy-selenium套件
而Scrapy框架想要使用Selenium套件來發送請求(Request)與接收回應(Response),就需要一個Middleware來使用Selenium套件,如下圖黃框的地方:
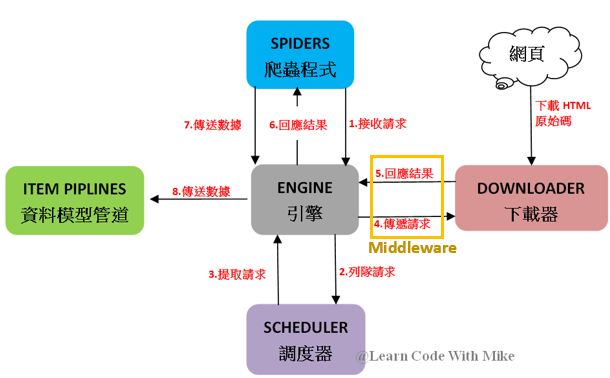
所以,Scrapy框架想要使用Selenium套件來發送請求與接收回應結果,就需要定義Middleware,當然,已經有大大寫好了scrapy-selenium Middleware可以使用,安裝方式如下指令:
$ pip install scrapy-selenium
接下來,前往下載Selenium的瀏覽器驅動,並且放置於Scrapy專案資料夾中,如下圖:

開啟settings.py檔案,加入scrapy-selenium Middleware的相關設定,如下範例:
DOWNLOADER_MIDDLEWARES = {
'scrapy_selenium.SeleniumMiddleware': 800
}
SELENIUM_DRIVER_NAME = 'chrome' #瀏覽器名稱
SELENIUM_DRIVER_EXECUTABLE_PATH = 'chromedriver.exe' #驅動程式路徑
SELENIUM_DRIVER_ARGUMENTS = ['-headless']三、Scrapy整合Selenium爬取動態網頁
前往Accupass網站首頁,如下圖:

在活動標題的地方,點擊右鍵,選擇「檢查」,可以看到HTML原始碼如下:

import scrapy from scrapy_selenium import SeleniumRequest
而想要讓Scrapy框架使用Selenium套件發送請求,就可以新增start_requests()方法(Method),如下範例:
import scrapy
from scrapy_selenium import SeleniumRequest
class AccupassSpider(scrapy.Spider):
name = 'accupass'
allowed_domains = ['accupass.com']
start_urls = ['http://accupass.com/']
def start_requests(self):
yield SeleniumRequest(url='https://www.accupass.com/?area=north', callback=self.parse)以上範例的第11行,callback參數就是收到網頁的回應結果之後,所要執行的方法(Method),也就是爬取網頁上的資料,如下範例:
import scrapy
from scrapy_selenium import SeleniumRequest
class AccupassSpider(scrapy.Spider):
name = 'accupass'
allowed_domains = ['accupass.com']
start_urls = ['http://accupass.com/']
def start_requests(self):
yield SeleniumRequest(url='https://www.accupass.com/?area=north', callback=self.parse)
def parse(self, response):
titles = response.css("p.style-f13be39c-event-name::text").getall() #爬取所有活動標題
for title in titles:
print(title) #印出活動標題截取部分執行結果

四、小結
Scrapy框架透過scrapy-selenium Middleware,整合了Selenium套件的功能後,即可爬取像是JavaScript產生的動態網頁,並且享有非同步的爬取效率。大家實作完本文,可以接續將資料存入資料庫或匯出至檔案,進行更多的資料分析應用唷。更多有關scrapy-selenium Middleware的使用方式可以參考https://github.com/clemfromspace/scrapy-selenium。
如果您喜歡我的文章,別忘了在下面訂閱本網站,以及幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
- [Scrapy教學1]快速入門Scrapy框架的5個執行模組及架構
- [Scrapy教學2]實用的Scrapy框架安裝指南,開始你的第一個專案
- [Scrapy教學3]如何有效利用Scrapy框架建立網頁爬蟲看這篇就懂
- [Scrapy教學4]掌握Scrapy框架重要的CSS定位元素方法
- [Scrapy教學5]掌握Scrapy框架重要的XPath定位元素方法
- [Scrapy教學6]解析如何在Scrapy框架存入資料到MySQL教學
- [Scrapy教學7]教你Scrapy框架匯出CSV檔案方法提升資料處理效率
- [Scrapy教學8]詳解Scrapy框架爬取分頁資料的實用技巧
- [Scrapy教學9]一定要懂的Scrapy框架結合Gmail寄送爬取資料附件秘訣
- [Scrapy教學10]不可不知的Scrapy框架爬取下一層網頁資料實作
- [Scrapy教學11]學會使用3個Scrapy網頁爬蟲偵錯技巧提升開發效率




大大,在pip install scrapy-selenium的scrapy少一個r喔~
回覆刪除已更正,感謝提醒 :)
刪除請問
回覆刪除titles = response.css("p.style-f13be39c-event-name::text").getall()
為什麼改成xpath選取,如下
titles = response.xpath("//p[@class='style-f13be39c-event-name']/text()").getall()
會沒辦法順利print呢